Actionable Intelligence
Critical Contextual Note: The provided research paper is a perspective and theoretical framework for a diagnostic tracking system (the “N-of-1 analyzer” and biological digital twins). The intelligence below translates the paper’s diagnostic intervention (Multi-omic tracking) into your required parameters.
- The Translational Protocol (Rigorous Extrapolation):
-
Biomarker Verification:
-
Target Engagement: The “target” is the successful mapping of an individual’s biological baseline. Verification requires longitudinal stability across 11,000+ proteins (e.g., via SomaScan or Olink aptamer arrays), high-resolution metabolomics, and stable epigenetic methylation clocks.
-
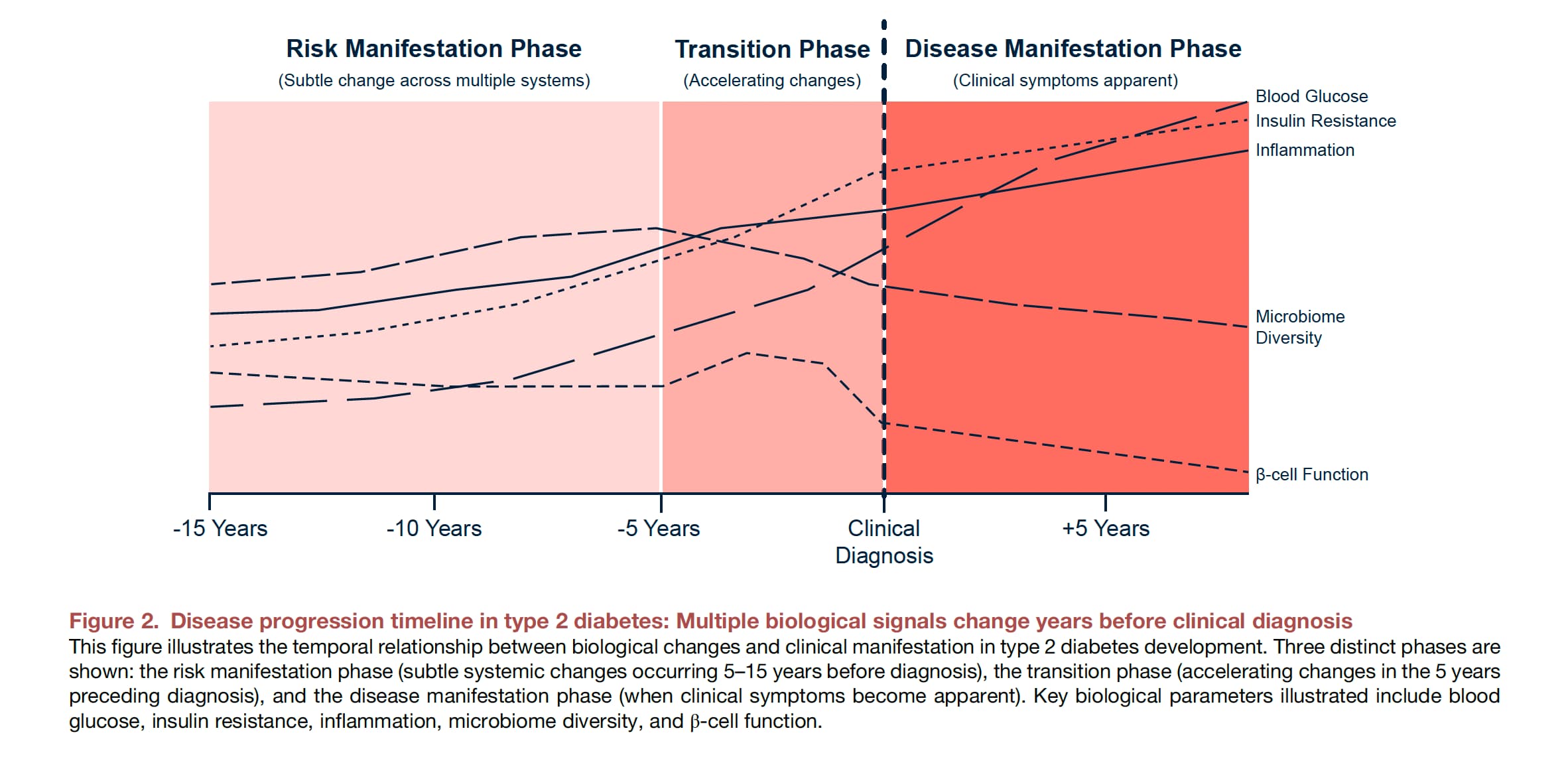
Divergence Signals: Successful deployment identifies subtle, pre-symptomatic shifts in systemic inflammation (e.g., multiplexed cytokine drift), declining insulin sensitivity (metabolomic lipid/amino acid shifts prior to HbA1c elevation), and organ-specific age acceleration.
-
Feasibility & ROI:
-
Sourcing: Commercially available but highly fragmented. Next-generation plasma proteomics and multi-omic testing are available through specialized preventative clinics and direct-to-consumer health tech companies (e.g., Function Health, Thorne). Wearable data streams are commoditized (Oura, Apple, Whoop, Garmin/Coros).
-
Cost vs. Effect: Poor short-term ROI. Comprehensive multi-omic profiling currently costs $1,000 to $5,000 per assessment. To achieve the high-frequency temporal mapping required by the N-of-1 framework, annual costs could exceed $20,000–$50,000 per patient, making it accessible only to elite biohackers or concierge medical practices until sequencing costs drop further.
Part 5: The Strategic FAQ
1. False Positives: How does the N-of-1 analyzer practically mitigate alert fatigue when tracking 11,000 proteins longitudinally, given that standard statistical corrections (like Bonferroni) still yield mathematically inevitable false positives?
Answer: The framework proposes a multi-layered filtering system. It requires temporal validation (anomalies must persist across multiple, consecutive time points) and biological coherence (changes must align with known, correlated pathways rather than isolated spikes). It also uses a tiered alert system, flagging only highest-confidence, actionable divergences for immediate clinical attention.
2. Economic Viability: With multi-omic assessments costing thousands of dollars per draw, how can this framework achieve the necessary sampling frequency without becoming financially prohibitive?
Answer: The authors acknowledge this as a massive hurdle. In the near term, adoption will likely be restricted to employer-sponsored wellness programs, clinical trials, and self-pay concierge markets. Long-term viability relies entirely on technological scaling driving costs down to a fraction of current prices, similar to the historical cost curve of whole-genome sequencing.
3. Regulatory Clearance: How can an adaptive, continuously learning AI algorithm pass FDA clearance when current regulatory pathways (like the 510(k)) are historically designed for “locked” models?
Answer: The FDA is currently evolving its approach via Predetermined Change Control Plans (PCCPs), which allow developers to pre-specify how an AI will learn post-market. The authors pragmatically suggest deploying the N-of-1 analyzer initially as a “locked” CLIA-certified laboratory-developed test (LDT) to bypass immediate bottlenecks, using the gathered real-world evidence to eventually seek broader Software-as-a-Medical-Device (SaMD) approval.
4. Digital Twin Training Bias: Baseline genetic data (like GWAS) and existing omic reference ranges are heavily skewed toward European ancestries. Won’t these digital twin simulations hallucinate or fail when applied to admixed or non-European populations?
Answer: Yes. The paper explicitly warns that applying Polygenic Risk Scores (PRS) and associated models derived from European cohorts to African or Asian ancestries results in significantly reduced predictive accuracy. An equitable N-of-1 system requires training foundational AI models on massively diverse, globally representative datasets.
5. Wearable Data Quality: Wearables use proprietary, “black-box” algorithms to estimate metrics like HRV and sleep. How can the N-of-1 analyzer trust this data if the raw inputs are obscured by consumer tech companies?
Answer: While consumer wearables provide excellent longitudinal trend tracking relative to an individual’s baseline, the lack of raw data access is a barrier to rigorous mechanistic science. The N-of-1 framework relies heavily on the algorithm’s ability to learn an individual’s unique variance patterns across these devices, prioritizing relative deviation over absolute, cross-platform algorithmic accuracy.
6. The “Missing Heritability” Gap: The paper notes genetics explain only a fraction of phenotypic variance (like height or longevity). How does the digital twin account for unmeasured epigenetic or environmental (exposome) factors?
Answer: The system bypasses the need to measure every historical environmental exposure by focusing on high-frequency phenomics (current proteomics, metabolomics, and transcriptomics). These dynamic fluid markers serve as the integrated, real-time functional readout of how genetic risks are currently interacting with unmeasured lifestyle and environmental stressors.
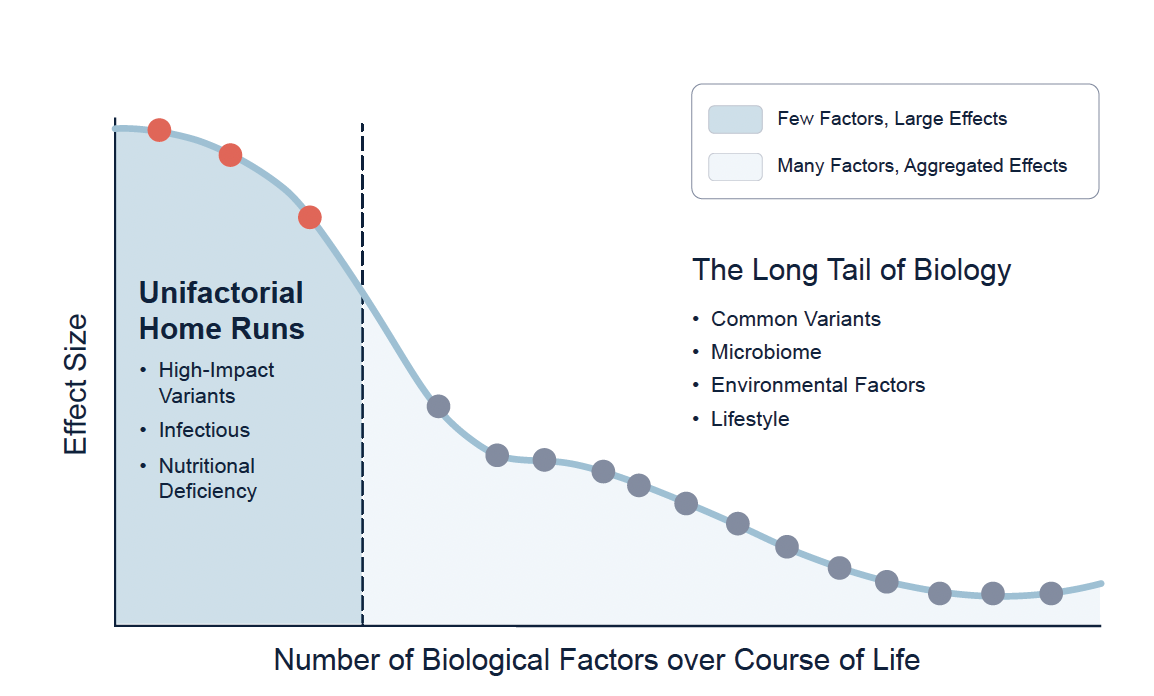
7. Actionability of the “Long Tail”: If the system flags a divergence in an obscure molecular pathway, what is the clinical utility if no targeted precision drug exists to fix it?
Answer: This remains a critical translational gap. The system uses knowledge-graph-augmented LLMs to suggest mechanistic connections, but often the only intervention for “long tail” metabolic drift is generalized, non-specific lifestyle modification (sleep, diet, exercise) rather than a novel therapeutic.
8. Clinical Bandwidth: Who acts as the interpreter? Standard primary care physicians lack the time, infrastructure, and bioinformatics training to interpret a digital twin’s multi-omic divergence report.
Answer: The framework fundamentally relies on the AI acting as a “reasoning partner” capable of contextualizing and distilling vast datasets into clear, actionable recommendations. Without an autonomous AI triaging the data, the system would instantly overwhelm human clinical bandwidth.
9. Differentiating Adaptive vs. Maladaptive Drift: As humans age, some omic shifts are compensatory rather than pathological. How does the algorithm differentiate a healthy adaptation from early disease?
Answer: This requires deep, longitudinal contextualization. For instance, the paper notes that gut microbiomes become increasingly unique in healthy aging; attempting to force it back to a “young” baseline can be counterproductive. The digital twin must be trained on trajectories of healthy agers to recognize and preserve compensatory adaptations.
10. Microbiome Volatility: The gut microbiome shifts daily based on acute variables like diet and travel. How does the system establish a “baseline” for something so intrinsically noisy?
Answer: By capturing dense, dynamic data clouds over long periods, the N-of-1 analyzer uses temporal analysis to smooth out transient noise. It focuses on persistent shifts in the functional capacity of the microbiome (e.g., long-term inflammatory signaling) rather than day-to-day taxonomic fluctuations.
Interaction Check: Longevity Stack Confounding
When cross-referencing this framework with common biohacker longevity stacks (Rapamycin, SGLT2i, Metformin, Acarbose, 17-alpha estradiol, PDE5i), a unique systemic conflict arises: Algorithmic Confounding. These geroprotectors radically alter baseline human physiology. Rapamycin suppresses mTOR, fundamentally shifting lipid metabolism and immune signatures; SGLT2 inhibitors and Acarbose aggressively alter glucose dynamics and the gut metabolome. If an individual’s digital twin is not explicitly trained to recognize these drug-induced states as a “biohacked baseline,” the N-of-1 analyzer will flag these artificially induced multi-omic profiles as pathological divergence, triggering massive false-positive cascades.