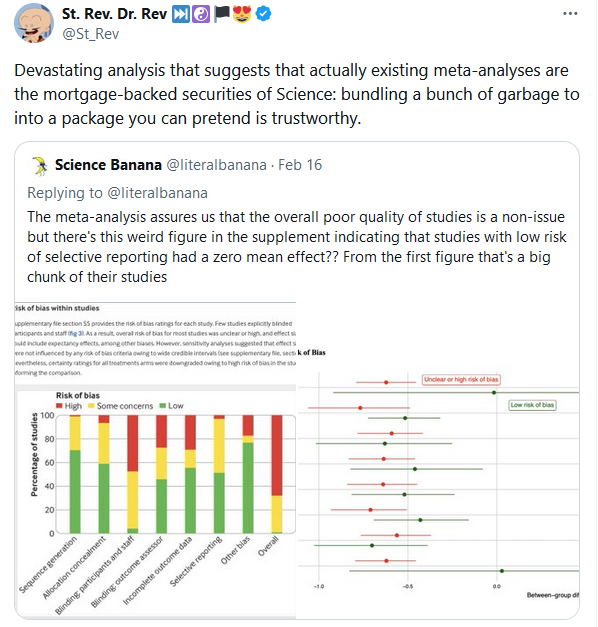
This is what I intuitively feel after reading a lot of scientific content as well and seeing the arguments based on published or no published literature. It is totally true that most research or scientific content is false. The best we can do is large randomized controlled trials. The worst is mendelian randomization.
Does that mean no one takes rapamycin ever? No but about 80% of the other stuff or the other arguments should probably be disregarded if the limitations are not clearly stated. No one bothers to state the limitations of what they say or write it seems.
It reminds me of the old saying “50% of advertising expenditures are a complete waste of money, the problem is you don’t know which 50%”.
Ultimately you have to make decisions with uncertainty, and the best information available. Well-done scientific papers are the best sources we have, though of course imperfect and incomplete.
But that seems to be simply restating that in any large sample of research papers, there will always be a small percent that are high impact, high certainty.
Just by the fact that we discuss most new aging-related research papers will mean that the same distribution curve will be seen in what we discuss. I still think there is value in discussing the new papers related to aging. But yes, always good to keep in mind the sample size, nature of the study, source of the study, etc (factors that go into a “high impact” or “high certainty” study.
So, I’d like to say that this research finding seems false. I believe the correct number for false Western studies is about 15%, not 50% (see rebuttals below). If you want 50% or higher look to China, Russia and N. Korea. So, when the author of a study is falsifying the number of falsifications, I’ll throw the whole heap in the rubbish bin. Hey, there’s at least a 50% chance his research is false too!
If you’d like more information, there’s a whole Wikipedia article here:
Here’s a sample rebuttal:
Biostatisticians Jager and Leek criticized the model as being based on justifiable but arbitrary assumptions rather than empirical data, and did an investigation of their own which calculated that the false positive rate in biomedical studies was estimated to be around 14%, not over 50% as Ioannidis asserted.[12] Their paper was published in a 2014 special edition of the journal Biostatistics along with extended, supporting critiques from other statisticians. Leek summarized the key points of agreement as: when talking about the science-wise false discovery rate one has to bring data; there are different frameworks for estimating the science-wise false discovery rate; and “it is pretty unlikely that most published research is false”, but that probably varies by one’s definition of “most” and “false”.[13]
Statistician Ulrich Schimmack reinforced the importance of the empirical basis for models by noting the reported false discovery rate in some scientific fields is not the actual discovery rate because non-significant results are rarely reported. Ioannidis’s theoretical model fails to account for that, but when a statistical method (“z-curve”) to estimate the number of unpublished non-significant results is applied to two examples, the false positive rate is between 8% and 17%, not greater than 50%.[14]
However, it’s good to apply some skepticism here.
DeStrider’s Corollaries:
RCT studies always do a Phase 1 safety study to determine if a substance is safe for human use. So all successful Phase 3 studies have proven short-term safety.
Even if results are not real, there is always the placebo effect which confers about a 30% benefit.
Given that there is high safety and a high chance of benefit (real or placebo) for a reported RCT trial, the only thing you are truly wasting by giving an RCT-tested supplement/medication/therapy a shot is money and time.
Odds are higher that you’ll be able to have at least one winner if you try a wide range of ‘proven’ RCT-trialed substances.
It’s Pascal’s Wager for each supplement and I’ve got a lot of chips to spend at this casino.
Because I don’t want to cash in my chips early.
This is also the thought process behind venture capital. For every 20 they fund, they hope to get at least 1 winner and that winner makes up for all the failures.
Depends what you call “false”. They might make mistakes, omit things, be biased, etc. and the paper would not be “false” but lead to a wrong conclusion. This is also common in articles in the West. But yeah, Western papers tend to be of higher quality. (I don’t think that North Koreans publish papers) In general, I consider that about a third of papers are wrong, so I want 3 papers by different teams going in the same direction to be “convinced” of something. Below that, it’s just some signal.
I think you need to watch the video. The point is that the cause is not fraud but pure chance. Like when you start testing with a low a priori chance you will find a lot of false positive results and the positive predictive value will be low. Besides that there are other biases, like the pressure to publish positive new results which leads to p-hacking and not publishing of negative results