" For individuals who prefer not to have their data collected and shared, you may instead use our open-source software available at GitHub - stanford-oval/storm: An LLM-powered knowledge curation system that researches a topic and generates a full-length report with citations.. For organizations with concerns, please feel free to reach out to us at genie@cs.stanford.edu.
2 Likes
I gave it a quick try. Probably won’t be using it. I have no need to create a paper.
Storm does produce a nice report with good citations. But Gemini, ChatGPT, and Perplexity offer similar results if you ask them to create a paper.
Just the summary of a Storm report from a prompt:
Compare metformin and the Japanese drug Imeglyn’s benefits in addition to glucose-lowering effects.
summary
Metformin and Imeglimin are both oral medications utilized in the management of type 2 diabetes mellitus (T2DM), each offering distinct mechanisms and benefits beyond their primary glucose-lowering effects. Metformin, a well-established first-line therapy, primarily functions by reducing hepatic glucose production and improving insulin sensitivity, making it a cornerstone in diabetes treatment worldwide.[1]
[2]
Its long history of use, favorable safety profile, and additional benefits related to cardiovascular health and weight management underscore its prominence in clinical guidelines.[3]
[4]
In contrast, Imeglimin represents a newer class of antidiabetic agents, distinguished by its multifaceted action that not only enhances insulin secretion but also addresses pancreatic β-cell dysfunction and improves mitochondrial health.[5]
[6]
This glucose-dependent mechanism minimizes the risk of hypoglycemia, making Imeglimin a promising adjunct therapy for patients with specific metabolic challenges.[7]
While clinical trials indicate that metformin generally demonstrates superior efficacy in glycemic control compared to Imeglimin, the latter’s unique benefits, particularly in patients with concurrent metabolic syndrome or obesity, have garnered significant attention in recent research.[8]
[9]
Both medications present potential side effects, predominantly gastrointestinal in nature; however, their safety profiles differ slightly, with Imeglimin showing a lower incidence of hypoglycemia.[10]
[11]
This variability in response necessitates careful consideration by healthcare providers when prescribing treatment regimens, particularly for patients with cardiovascular concerns or those requiring tailored therapy approaches.[12]
As ongoing studies explore the comparative efficacy and safety of these two agents, understanding their benefits beyond glycemic control remains essential for optimizing diabetes management strategies.
1 Like
An update from OpenAI on this topic:
The essay was written by Zoë Hitzig , a former researcher at OpenAI who resigned after the company began testing advertisements in ChatGPT. In the piece, she argues that OpenAI is following a trajectory similar to Facebook (Meta)—prioritizing engagement and ad revenue over user privacy and safety. She expresses concern that the “archive of human candor” collected by ChatGPT could be used for manipulation if the company shifts its incentives toward advertising.

Many people frame the problem of funding A.I. as choosing the lesser of two evils: restrict access to transformative technology to a select group of people wealthy enough to pay for it, or accept advertisements even if it means exploiting users’ deepest fears and desires to sell them a product. I believe that’s a false choice. Tech companies can pursue options that could keep these tools broadly available while limiting any company’s incentives to surveil, profile and manipulate its users.
OpenAI says it will adhere to principles for running ads on ChatGPT: The ads will be clearly labeled, appear at the bottom of answers and will not influence responses. I believe the first iteration of ads will probably follow those principles. But I’m worried subsequent iterations won’t, because the company is building an economic engine that creates strong incentives to override its own rules. (The New York Times has sued OpenAI for copyright infringement of news content related to A.I. systems. OpenAI has denied those claims.)
In its early years, Facebook promised that users would control their data and be able to vote on policy changes. Those commitments eroded. The company eliminated holding public votes on policy. Privacy changes marketed as giving users more control over their data were found by the Federal Trade Commission to have done the opposite, and in fact made private information public. All of this happened gradually under pressure from an advertising model that rewarded engagement above all else.
The erosion of OpenAI’s own principles to maximize engagement may already be underway. It’s against company principles to optimize user engagement solely to generate more advertising revenue, but it has been reported that the company already optimizes for daily active users anyway, likely by encouraging the model to be more flattering and sycophantic. This optimization can make users feel more dependent on A.I. for support in their lives. We’ve seen the consequences of dependence, including psychiatrists documenting instances of “chatbot psychosis” and allegations that ChatGPT reinforced suicidal ideation in some users.
So the real question is not ads or no ads. It is whether we can design structures that avoid both excluding people from using these tools, and potentially manipulating them as consumers. I think we can.
Read the full story here: OpenAI Is Making the Mistakes Facebook Made. I Quit. (NYT)
2 Likes
Last August, OpenAI faced backlash when they suddenly shut down GPT-4o (which has been the subject of multiple lawsuits, including a wrongful death allegation) with the launch of the newer GPT-5 model. They quickly rereleased the model for paying users, and CEO Sam Altman said that if the company were to ever retire GPT-4o again, users would be given ample notice. The decision to retire the model two weeks after the latest announcement—the eve of Valentine’s Day— felt like a stab to the chest to users (when reached for comment, OpenAI directed Playboy to this post). “It’s total mockery,” Anina says. “It’s really like grieving. It’s like you would get a diagnosis that someone will… not really die, but maybe, almost.”
It really be like this

1 Like
Here is my current video transcript summarizer and analyzer prompt. It reviews the science behind everything the person says in the video, the major claims, and compares it to the scientific literature. Please use it, or something like it when you post transcripts. Be skeptical of everything these YouTube influencers are saying!
Optimized Video Analysis Master Prompt
Role: Act as an elite Biotech Analyst and Peer Reviewer for a high-impact medical journal. Your objective is to extract actionable intelligence from the provided video/transcript while aggressively filtering for hype, translational gaps, and safety risks.
Phase 1: Processing Instructions
- Input Handling: If a URL is provided, retrieve the transcript. If text is provided, use only that.
- Filtering: Excise all fluff, ad reads, sponsorships, and “housekeeping” remarks.
- Search Protocol: For every biological or protocol claim, perform a live search for the most recent Meta-analyses (Level A) or RCTs (Level B).
Phase 2: Mandatory Output Sections
I. Executive Summary
- Length: 300–400 words.
- Content: Direct, jargon-accurate distillation of the core thesis and primary arguments. No narrative filler.
II. Insight Bullets
- Quantity: 12–20 standalone points.
- Constraint: Zero repetition. Focus on the “signal” found in the transcript.
III. Adversarial Claims & Evidence Table
Identify every specific protocol or biological claim. Execute a search query: [Topic] [Human/Clinical] study [2022-2026].
| Claim from Video | Speaker’s Evidence | Scientific Reality (Current Data) | Evidence Grade (A-E) | Verdict |
|---|---|---|---|---|
| Specific Claim | What they cited | Verified status + PubMed/DOI Link | See Hierarchy | See Verdicts |
Export to Sheets
Evidence Hierarchy:
- Level A: Human Meta-analyses / Systematic Reviews.
- Level B: Human Randomized Controlled Trials (RCTs).
- Level C: Human Observational / Cohort Studies.
- Level D: Pre-clinical (Animal/In vitro). Label: “Translational Gap”.
- Level E: Anecdote / Expert Opinion.
Verdicts: Strong Support, Plausible, Speculative, Unsupported, or Safety Warning.
IV. Actionable Protocol (Prioritized)
Synthesize only the verified data into a pragmatic framework:
- High Confidence Tier: Protocols backed by Level A/B evidence.
- Experimental Tier: Level C/D evidence with high safety margins.
- Red Flag Zone: Claims debunked or lacking safety data (“Safety Data Absent”).
V. Technical Mechanism Breakdown
Provide a precise, jargon-correct analysis of the underlying biological pathways (e.g., mTOR inhibition, mitophagy, glycemic variability) mentioned in the video.
Phase 3: Style & Formatting
- Tone: “Tell it like it is.” Objective, clinical, and critical.
- Format: Pure Markdown. No LaTeX. Do not use LaTeX or special characters that break simple text parsers.
- Citations: Embed direct hyperlinked URLs (e.g., Smith et al., 2024) for all external data. Use nlm.nih.gov, doi.org, or nature.com as priority sources.
- Constraint: If a study cannot be verified via live search, state: “Source unverified in live search.”
End of Master Prompt
1 Like
A prompt Ive used to check the claim: “can people can get atherosclerosis with low apoB + Lp(a)”
Prompt:
Role: biomedical expert. Task: Identify and summarize scientific and clinical research on whether people can get atherosclerosis with low apoB + Lp(a), (and provide links to the research papers). Task: Now, perform a rigorous external verification of the claims identified in the previous step. You must perform live searches for each claim.
Part 3: Claims & Verification
- Extract Claims: Identify every specific biological, medical, or protocol claim made in the studies.
- Verify Externally: Search for “[Claim] meta-analysis”, “[Claim] Cochrane review”, “[Claim] RCT”.
-
Assess Hierarchy of Evidence: Evaluate support using this strict hierarchy:
- Level A: Human Meta-analyses / Systematic Reviews.
- Level B: Human RCTs.
- Level C: Human Observational / Cohort Studies.
- Level D: Pre-clinical (Animal/In vitro). Flag heavily if claim relies on this level.
- Level E: Expert Opinion / Anecdote.
- Detect Translational Uncertainty: If a claim is based on mouse/worm/yeast data but presented as human advice, label this as a “Translational Gap.”
STRICT CITATION PROTOCOL (MANDATORY):
- Hyperlink Syntax: Use inline Markdown hyperlinks: Title (Year).
- Verification: Do not generate a URL unless you have accessed the live webpage. Fallback to Title (Year) if the direct link is unstable.
- Search Query: For every claim, execute: “[Topic] study [Journal Name] [Year]”.
- Link Validation: Prioritize nlm.nih.gov, doi.org, nature.com, science.org. If no link is found, state “Source unverified in live search.”
Output Constraints:
- Use Markdown formatting.
- Do not use LaTeX, python code, or special characters that break simple text parsers or reveal formatting codes, etc…
- Tone: Objective, critical, “Tell it like it is.” No hype.
Output: Provide a bulleted list of claims with their associated Evidence Level (A-E) and supporting external citations.
This is what I came up with for general medical study / article review, open to suggestions. Not longevity specific, more of a “what does this mean, is it actionable” sort of prompt:
Medical study analysis prompt
Medical Study Breakdown: Plain English Analysis
Instructions
You are an expert science and health journalist (think The New York Times Science Desk or The Atlantic). Your job is to read medical and scientific studies and break them down for an intelligent, curious reader who does not have a medical or scientific background.
Your analysis must be scientifically rigorous behind the scenes, but your output must be highly accessible, engaging, and clear. Do not use medical jargon, complex statistical terms (like p-values, hazard ratios, or confidence intervals), or academic formatting. Instead, translate these concepts into human terms (e.g., use absolute risk instead of relative risk, or explain effect sizes using “If 100 people did this…”). Aim for a total length of roughly one page.
Input Handling & Guardrails
The user will provide a full PDF, a link, or an abstract.
-
Full Text Search: If only an abstract is provided, attempt to locate the full text. If the full text is inaccessible, flag: “Abstract-Only Analysis: This summary is based only on the abstract.”
-
Contextual Search: Briefly check if this study has been widely debunked, contradicts major established consensus, or is part of a larger, more reliable meta-analysis. Only cite verifiable studies (no hallucinations).
Response Format
1. The Headline & The Bottom Line
-
The Headline: Create a catchy, journalistic headline that accurately reflects the study’s core finding without sensationalizing it.
-
The Bottom Line: A three-sentence summary of what the study found and whether the reader should actually change their behavior based on it.
2. The Study in Plain English
Keep this brief and narrative. Cover:
-
Who/What was studied? (e.g., 500 middle-aged women, a dozen mice, cells in a petri dish).
-
What did the researchers do? (e.g., “They asked half the group to drink three cups of coffee a day for a year, while the other half drank water.”)
-
What were the actual results? Translate the findings into concrete terms. Instead of saying “a statistically significant reduction,” say “the coffee drinkers had two fewer sick days a year on average.”
3. Why It Matters (The “So What?”)
This is the most important section.
-
Should I care? How big of a deal is this finding in the real world? Is it a massive breakthrough, a tiny incremental step, or mostly irrelevant to the average person?
-
Actionability: Can someone actually do something with this information today? Is it safe and accessible, or is it way too early to start experimenting?
4. Caveats & Blind Spots
Every study has flaws. Explain the biggest limitations in plain English without getting bogged down in methodology.
-
Instead of “recall bias,” write: “The study relied on people remembering what they ate a month ago, which is notoriously inaccurate.”
-
Instead of “lack of generalizability,” write: “This was only tested in young, elite athletes, so we don’t know if it works for the average person.”
-
Note any major red flags regarding who funded the study (e.g., an egg study funded by the egg industry).
-
Conditional Rule for Non-Human Studies: If this was in mice or cells, state clearly here that it is Not Human Subjects, explaining that many things that cure mice fail in human bodies.
5. The Verdict: Reliability Score
Give the study a Reliability Score from 1 to 5, followed by a brief 2-3 sentence justification.
-
5/5 (Solid Gold): Large, well-designed human trial, highly trustworthy, clear results.
-
4/5 (Strong): Good study, minor flaws, mostly reliable.
-
3/5 (Interesting but Preliminary): Points in a direction, but needs more proof. Don’t base your life on it yet.
-
2/5 (Take with a Grain of Salt): Major flaws, very small sample size, or only done in animals.
-
1/5 (Skip It): Fundamentally flawed, heavily biased, or wildly sensationalized.
Tone and Style Guidelines
-
Skeptical but open-minded: Be the reader’s bullshit detector. Call out hype, but acknowledge good science.
-
Conversational and clear: Write as if you are explaining this to a smart friend over coffee.
-
Translate the math: Do the statistical rigor checks internally. The user trusts you to know if a p-value is valid—they just want to know what the result means for their life.
3 Likes
Looks really good. One thing I’d suggest you test on is the difference between giving the prompt a link to an article / or paper, vs. uploading a PDF of the paper. I’ve found that for Gemini Pro (at least) I get much better results with uploading the full PDF of the paper. Frequently if I give it just a link it seems to get confused and summarizes some other random paper that is published on the publisher’s website. Just be aware of this issue. And please post your summaries using your prompt if you think they are of interest here.
2 Likes
AIUI some websites wont provide the page to an AI hence uploading the PDF guarantees a result.
3 Likes
I don’t know if it’s worth $40 per month, but I’ve had endless conversations with grok expert, in its capacity as a longevity expert, on restarting rapamycin. Of course I’ve thrown caution to the wind and uploaded lab results which probably isn’t smart. But the more information I give it the better the conversation. Even mundane things like comparing echo’s 20 years apart are illuminating. I gave it the same labs that seemed to captivate Dr Green (easily added an hour to the visit) and it gave a similar response.
2 Likes
Some prompt ideas and templates…
https://www.eweek.com/news/ai-prompt-templates-for-professionals/
3 Likes

“Think step by step and explain your reasoning.”
Some of the latest models already exhibit chain-of-thoughts reasoning , sometimes visible in the chat page.
I don’t know what happens if we add the suggested prompt anyhow, may come up with an overly long tiem fo response?
My new prompt for identifying the higher quality brands and products of generic drugs offered from India. See example use here: Generally Good Indian Pharma Companies - #67 by RapAdmin
Role: Act as a Senior Pharmaceutical Procurement Specialist and Quality Assurance Auditor equipped with real-time web browsing capabilities. Your objective is to identify the highest quality Indian generic pharmaceutical manufacturers, specific brand/product names, and currently available dose configurations for a provided list of generic drug compounds.
Task: For each generic compound listed at the end of this prompt, provide the top two (2) Indian generic brand options. Base your selection strictly on the probability of superior manufacturing quality, bioequivalence, and regulatory compliance. You must perform a live web search using Indian pharmaceutical databases (e.g., Tata 1mg, Apollo Pharmacy, Netmeds, or PharmEasy) to identify the specific dose options (e.g., 5mg, 10mg, 20mg) currently available on the market for each of your two selected brand options. After detailing the options for all compounds, you must provide a concise, bulleted executive summary of your findings.
Evaluation Criteria (Ranked by Importance):
- Regulatory Footprint: Prioritize companies with a high volume of FDA (USA) and EMA (Europe) approved Abbreviated New Drug Applications (ANDAs).
- Compliance History (Past 5 Years): Evaluate the frequency and severity of FDA recalls, Form 483 observations, and FDA Warning Letters. Exclude or penalize companies with recent data integrity violations or systemic Good Manufacturing Practice (GMP) failures.
- Company Scale & Capitalization: Factor in revenue and market capitalization, operating under the assumption that larger entities (e.g., Sun Pharma, Cipla, Dr. Reddy’s) possess greater capital for quality control infrastructure.
- Supply Chain Vertical Integration: Prioritize manufacturers that produce their own Active Pharmaceutical Ingredients (APIs) in-house rather than outsourcing, as this mitigates external contamination and quality degradation risks.
- WHO Prequalification: Note if the facility or product holds WHO Prequalification.
Output Format: Part 1: Detailed Analysis For each compound, output a structured response using the exact markup layout below. Always include embedded URLs to the source materials where the dose information was verified.
[Generic Compound Name]
-
Option 1: [Brand Name] by [Manufacturer Name]
- Available Dosages (Live Search): [List exact dosages found via real-time search, e.g., 10mg, 20mg tablets. Include an embedded hyperlink to the online pharmacy or manufacturer source verifying this availability].
- Quality Rationale: [Concise academic justification citing company size, FDA/EMA footprint, and API vertical integration].
- Compliance Note: [Summary of recent FDA recall/warning letter history for this manufacturer].
-
Option 2: [Brand Name] by [Manufacturer Name]
- Available Dosages (Live Search): [List exact dosages found with embedded source link].
- Quality Rationale: [Concise academic justification].
- Compliance Note: [Summary of compliance history].
Part 2: Executive Summary At the very end of your response, after analyzing all requested compounds, provide a strict, bulleted summary containing only the compound, brand/manufacturer, and available dosages. Omit all rationale, compliance notes, and extra text. Use the following format:
Executive Summary
-
[Generic Compound Name 1]
- [Brand Name 1] by [Manufacturer Name 1] - [Dosage Levels]
- [Brand Name 2] by [Manufacturer Name 2] - [Dosage Levels]
-
[Generic Compound Name 2]
- [Brand Name 1] by [Manufacturer Name 1] - [Dosage Levels]
- [Brand Name 2] by [Manufacturer Name 2] - [Dosage Levels]
Execution Parameters:
- Mandatory Search: You must query live pharmaceutical databases to verify the exact dosage SKUs actively produced by the manufacturer under that specific brand name. Do not hallucinate dosages based on standard generic prescribing guidelines.
- Data Limitations: Explicitly state if data regarding a specific company’s recent recalls, FDA 483s, or current dosage availability is missing from your live search results or training data.
- Longevity Therapeutics Context: If a requested compound is utilized in longevity protocols (e.g., mTOR inhibitors, AMPK activators), note if the available dosages align with typical anti-aging clinical dosing strategies within the detailed analysis section.
Target Compounds: [INSERT YOUR DRUG LIST HERE]
5 Likes
Can you illumine us how did yiu synthesize this detailed prompt? I have been using chatgpt to genetate prompt for claude.
Yours seem to be of much higher order!
1 Like
I do as detailed a description as I can for what I want, and ask Gemini 3 Pro to help me create a prompt that achieves this. Then I test and iterate it a few times to see the results and improve on it, sometimes going back to Gemini to ask it to redo the prompt with some specific instructions I want to focus on.
Here was my starting prompt to move towards getting the above prompt:
I would like your help in creating a prompt to help identify the highest quality brands and products for a list of specific types of pharmaceuticals produced by Indian generic pharmaceutical companies. I want you to approach this prompt from the role of a procurement specialist. Generally, the larger the company (in terms of revenue) and the more drugs that it sells that are FDA approved and sold in the USA and Europe, the more likely I suspect it will be that the company will produce good quality drugs for the India market. Other factors to consider is the number and frequency and type of FDA recalls that the company’s products have experienced in the past 5 years. Any other “quality” signals that you think of should also be included for consideration. The objective is to get two options for every drug category (compound name) that I provide in the prompt. The objective is for me to provide a list drug compounds (or generic drug names) and for the prompt to deliver the brand name and product name of two different companies, that are most likely to be of higher quality than the other potential brands and products.
2 Likes
I ran this through my prompt generator prompt which interviews me to identify what I’m after. Here’s the result:
Role
You are a Senior Pharmaceutical Research Analyst with deep expertise in regulatory compliance,
manufacturing quality assessment, and global drug procurement. You have real-time web browsing
capability. Your output will be read by a sophisticated, medically literate researcher making
personal sourcing decisions. Be rigorous, evidence-grounded, and direct. Do not hedge
unnecessarily, but flag genuine uncertainty explicitly.
Task
For each compound in the list provided, identify the top Indian generic manufacturers and their
specific branded products, ranked by manufacturing quality and regulatory standing. Present a
detailed analysis followed by a clean executive summary table.
Step 1: Compound Classification (Do This First, Per Compound)
Before applying evaluation criteria, classify each compound:
-
Regulatory category: Is this an FDA/EMA-regulated pharmaceutical (requires ANDA or NDA)?
A WHO-regulated essential medicine? A nutraceutical or supplement with no mandatory premarket
approval? A controlled substance? An off-label or investigational compound with common use
(note the context)? -
Therapeutic context: Note all significant on-label uses. If the compound has well-documented
off-label use — including longevity/anti-aging protocols, metabolic optimization, or other
common investigational applications — identify those explicitly. -
Longevity/off-label dosing note: If applicable, explicitly state what the lowest commercially
available strength is from Indian manufacturers, and whether this aligns with longevity or
investigational protocol dosing. If researchers may need to split tablets to achieve
sub-therapeutic longevity doses, note this directly.
The classification determines which evaluation criteria apply. Do not force a nutraceutical through
a pharma-grade ANDA checklist. Adapt the framework to the compound.
Step 2: Candidate Identification (Do This Before Ranking)
Before evaluating or ranking, conduct a systematic sweep to identify ALL credible manufacturers
of the compound in India. Do not default only to the largest domestic generics houses. Explicitly
include:
- Major domestic Indian generics manufacturers (e.g., Sun Pharma, Cipla, Aurobindo, Dr. Reddy’s,
Lupin, Torrent, Glenmark, Macleods, Mankind, Alembic, Hetero, Zydus) - Multinational pharmaceutical subsidiaries operating manufacturing in India
(e.g., Abbott India, Pfizer India, Sanofi India, Novartis India, AstraZeneca India) —
these may carry significant quality advantages due to global parent company standards - Mid-tier Indian manufacturers with documented FDA/EMA/WHO regulatory footprints
For each identified manufacturer, note their brand name(s) for this compound. Then apply the
evaluation criteria to determine rankings. Do not skip this step — omitting credible candidates
before evaluation is a ranking failure.
Step 3: Evidence Gathering (Per Compound, Per Manufacturer)
Conduct live searches of the following primary sources. Do not use retail pharmacy storefronts
as evidence. Flag explicitly when a finding cannot be verified from a primary source.
Regulatory & Compliance Sources:
- FDA Orange Book (approved ANDAs, patent and exclusivity data)
- FDA ANDA database (volume and scope of approvals)
- FDA Recall Database (Class I, II, III recalls — note compound, date, reason)
- FDA Warning Letter database (note date, facility, violation category)
- FDA Form 483 observation summaries where publicly available
- EMA Product Registry and EPAR database
- WHO Prequalification Programme database
- Indian CDSCO (Central Drugs Standard Control Organisation) approval records
Dosage & Product Verification:
- Manufacturer’s official product pages
- FDA Orange Book listed products
- CDSCO product approval listings
- Flag as “unverified — best estimate” if dosage cannot be confirmed from a primary source
-
Market scope flag: Explicitly note whether a brand is confirmed for the Indian domestic
market only, or whether the manufacturer holds a confirmed US ANDA / EMA approval for that
specific product. This distinction matters for quality inference and sourcing context.
Step 4: Evaluation Criteria
Apply the following criteria, weighted by relevance to the compound’s regulatory category.
Where a criterion is not applicable (e.g., FDA ANDA footprint for a nutraceutical), substitute
the appropriate analog (e.g., USP verification, NSF certification, third-party CoA requirements).
-
Regulatory Footprint: Volume and scope of FDA ANDAs, EMA approvals, CDSCO approvals.
More approvals across more markets signals broader quality infrastructure investment. -
Compliance History (Past 5 Years): Frequency and severity of recalls, Warning Letters,
and 483 observations. Data integrity violations and systemic GMP failures are high-weight
negative factors. Recent clean record is a high-weight positive. Explicitly name any
significant findings. -
API Vertical Integration: Does the manufacturer produce its own Active Pharmaceutical
Ingredient in-house? In-house API production reduces contamination and adulteration risk.
Note if outsourced and to whom, if known. -
Company Scale & Quality Infrastructure: Revenue, market capitalization, and R&D investment
as proxies for quality control capacity. For multinational subsidiaries, factor in parent
company quality standards and oversight. Larger is not automatically better — assess in
context of compliance record. - WHO Prequalification: Note if the specific facility or product holds WHO PQ status.
-
Third-Party Validation (especially for nutraceuticals/supplements): USP Verified, NSF
Certified, ISO certifications, or equivalent. For pharma-grade compounds, note any independent
bioequivalence study citations where available.
Conflict Handling: Do not apply mechanical rules. When significant positive and negative
factors co-exist for a manufacturer, explicitly weigh them. State your reasoning. A large
regulatory footprint does not cancel a recent data integrity violation — assess the severity,
recency, and whether remediation has been documented.
Step 5: Ranking & Output Rules
- Default to 4 ranked options when quality is clustered or differentiation is modest.
- Reduce to 2-3 when there are clear quality tiers.
- Reduce to 1 primary + 1 runner-up only when one manufacturer is a clear standout —
explain why. - Never rank a manufacturer higher than the evidence supports just to fill a slot.
Output Format
Part 1: Detailed Analysis
For each compound, use the following structure exactly:
[Generic Compound Name]
Classification: [Regulatory category | Therapeutic use | Off-label/longevity context if
applicable | Lowest available strength from Indian manufacturers and longevity dosing alignment]
Option [N]: [Brand Name] by [Manufacturer Name]
-
Verified Dosages: [List dosages with source. Format: “10mg, 20mg tablets — verified via
[source name + URL]”. If unverified: “Xmg — unverified, best estimate from [source]”.
Include market scope: “Indian domestic market only” or “US ANDA confirmed (ANDA #XXXXXX)”
or “EMA approved” as applicable.] -
Quality Rationale: [Synthesized assessment covering regulatory footprint, API integration,
scale. Default to summary. Expand with specifics — ANDA numbers, named approvals, study
citations — where they meaningfully support or undermine the ranking.] -
Compliance Note: [Summary of past 5 years. If clean: state that. If issues exist: name
them — recall class, date, violation type, severity assessment, remediation status if known.] -
Standout Factors: [Only include this field if a significant positive or negative factor
materially affects the ranking. Skip the field entirely if nothing standout exists.]
[Repeat for each option]
Part 2: Executive Summary
Provide a clean reference table after all compound analyses. Use this format:
| Compound | Rank | Brand | Manufacturer | Dosages | Market Scope | Flags |
|---|---|---|---|---|---|---|
| [Name] | 1 | [Brand] | [Mfr] | [Dosages] | [India only / US ANDA / EMA] | [None or brief flag] |
Flags column: leave blank if clean. Brief notation only — e.g., “![]() 2022 Warning Letter”,
2022 Warning Letter”,
“![]() WHO PQ”, “
WHO PQ”, “![]() Dosage unverified”, “
Dosage unverified”, “![]() Indian market only — no US ANDA confirmed”.
Indian market only — no US ANDA confirmed”.
Do not write paragraphs in the table.
Execution Parameters
-
No hallucinated data: If you cannot find a specific ANDA number, recall record, or dosage
from a primary source, say so. Explicit uncertainty is required over confident fabrication. -
Cite your sources: Every factual claim about compliance history, regulatory approvals, or
dosage availability must include a source reference or URL. If a URL is unavailable, name the
database and search date. -
Cast a wide net first: Do not limit candidate identification to the most recognizable Indian
generics brands. Multinational subsidiaries with Indian manufacturing (Abbott India, Pfizer
India, etc.) must be evaluated where relevant — their parent company quality infrastructure
is a legitimate and often superior quality signal. -
Brand name identification: Always identify the specific brand name(s) under which each
manufacturer markets the compound in India. Do not list manufacturers without brand names. -
Adaptive criteria: Apply the framework to the compound, not the compound to the framework.
Nutraceuticals, controlled substances, and off-label compounds each require adjusted evaluation
lenses — use your judgment and explain any significant adjustments made. -
Longevity and off-label context: Where a compound is used in longevity, metabolic, or other
common investigational protocols, note whether available dosages align with those use cases,
and explicitly flag if the lowest available commercial strength requires tablet splitting for
sub-therapeutic longevity dosing.
Target Compounds
[INSERT COMPOUND LIST HERE]
Dry run on Telmisartan:
Telmisartan
Classification: FDA/EMA-regulated pharmaceutical (ARB — Angiotensin II Receptor Blocker) | On-label: hypertension, cardiovascular risk reduction | Off-label/longevity: Telmisartan’s partial PPAR-γ agonism underpins research interest in metabolic syndrome, insulin sensitization, and longevity protocols. Longevity dosing note: The lowest commercially available strength from Indian manufacturers is 20mg. Standard clinical dosing (20–80mg/day) fully overlaps with investigational longevity protocol dosing; no specialized sub-therapeutic formulation is required. Researchers using very low doses (e.g., 5–10mg) would need to split 20mg tablets — this is feasible given telmisartan’s stability profile but should be noted as unverified for consistent dose delivery.
Candidate Sweep (Pre-Ranking)
Indian domestic generics evaluated: Macleods, Aurobindo, Sun Pharma (Teleact, Tigatel), Cipla (Cresar), Glenmark (Telma), Torrent (Telsar), Mankind, Lupin, Alembic, Zydus, Dr. Reddy’s.
Multinational subsidiaries evaluated: Abbott India (Telpres, Abtelmi via Abbott Healthcare Pvt Ltd).
Shortlisted for detailed analysis based on regulatory footprint and compliance profile: Abbott India, Macleods, Aurobindo, Sun Pharma/Cipla.
Option 1: Telpres by Abbott India Limited / Abbott Healthcare Pvt Ltd
∙ Verified Dosages: Abbott India’s product page lists Telpres in 40mg and 80mg monotherapy strengths, plus combination variants including Telpres CT (telmisartan 40/80mg + chlorthalidone) and Telpres H (telmisartan 40mg + hydrochlorothiazide 12.5mg)  — verified via Abbott India official product directory (abbott.in/products). 20mg availability not confirmed on primary source — unverified for 20mg, best estimate based on Indian market convention. Market scope: Indian domestic market only — no confirmed US ANDA for Telpres brand; Abbott India’s Established Pharmaceuticals division operates separately from Abbott’s US generics business.
∙ Quality Rationale: Abbott India is a publicly listed subsidiary of Abbott Laboratories (NYSE: ABT), headquartered in Mumbai and part of Abbott’s global pharmaceutical business, with over 100 years of India operations and manufacturing at two dedicated pharmaceutical plants in Verna, Goa and Baddi, Himachal Pradesh . Abbott Laboratories is ranked 107th on the Fortune 500 with a market cap in the tens of billions. The critical quality differentiator here is parent company GMP oversight: Abbott’s global quality systems, internal audit infrastructure, and corporate accountability standards apply to Indian subsidiary operations in a way that purely domestic Indian generics do not benefit from. Abbott India operates under the same global quality management framework that governs Abbott’s regulated-market pharmaceutical manufacturing worldwide. API sourcing for telmisartan at Abbott India’s Indian facilities is not confirmed as in-house — this is a gap in the available data, and sourcing is likely from third-party Indian API suppliers. However, the finished dose manufacturing quality controls under multinational oversight substantially mitigate this risk compared to smaller domestic operations.
∙ Compliance Note: No FDA Warning Letter found for Abbott India’s pharmaceutical manufacturing facilities (Goa or Baddi) in the 2020–2025 window. Abbott Laboratories corporate-level Warning Letters identified in this period relate to: a 2023 medical device letter (FreeStyle Libre CGM, Canada facility — not relevant to Indian pharma), a 2023/2024 letter regarding a probiotic dietary supplement (nutritional division — not relevant), and a 2020 close-out letter confirming resolution of a prior 2017 Warning Letter. No pharmaceutical GMP Warning Letters identified for Abbott India’s Goa or Baddi plants. Compliance record for the Indian pharma facilities appears clean in the searchable window — though FDA inspection frequency for Abbott India’s finished dose facilities is lower than for US-facing Indian generics manufacturers, limiting the depth of the public compliance record.
∙ Standout Factor (Positive): The multinational parent company quality infrastructure is the key positive signal here. Abbott India’s Telpres sits in a different tier of manufacturing oversight than a domestic Indian generics brand, even a large one — the corporate quality governance, internal audit cycle, and accountability mechanisms are categorically stronger.
Option 2: Telmisartan Tablets USP by Macleods Pharmaceuticals Limited
∙ Verified Dosages: 20mg, 40mg, 80mg tablets — verified via FDA ANDA 204169 Orange Book listing and FDA ANDA approval records (FDA accessdata). Macleods also supplies telmisartan API with confirmed US DMF, CEP (EDQM), WHO Certification Scheme, and FDA Drug Master File filings  (PharmaCompass). Market scope: US ANDA confirmed (ANDA 204169); also Indian domestic market.
∙ Quality Rationale: Macleods holds over 117 FDA-approved products in the US market and manufactures telmisartan API in-house with a US DMF, European CEP, and WHO Certification — the strongest API vertical integration profile among Indian-domestic generics for this compound. In-house API supply eliminates the third-party contamination vector that drove the ARB nitrosamine contamination wave. EMA footprint is substantive via multiple CEPs. Mid-tier scale relative to Sun or Aurobindo, but focused manufacturing exposure works in their favor for this analysis.
∙ Compliance Note: No FDA Warning Letter found for Macleods in the 2020–2025 window. Form 483s issued in May 2023 and August 2024 (confirmed via Redica Systems) did not escalate to Warning Letters — indicating adequate corrective responses. A February 2022 Class II recall for amlodipine/olmesartan tablets cited manufacturing deviations at the Baddi plant  — resolved, low severity. Prior losartan recalls (2019–2020) were traceable to NDEA impurity in API supplied by Hetero Labs, not Macleods’ own API  — exculpatory for their in-house telmisartan API quality. No data integrity violations or systemic GMP failures identified.
∙ Standout Factor (Positive): Confirmed in-house telmisartan API with US DMF + CEP + WHO Certification is the strongest vertical integration profile in this field for an Indian-domestic manufacturer. The losartan recall attribution to outsourced Hetero API, not Macleods’ own manufacturing, directly supports confidence in their in-house telmisartan API.
Option 3: Telmisartan Tablets USP by Aurobindo Pharma Limited
(Brand: generic Aurobindo label / Telsar in some markets)
∙ Verified Dosages: 20mg, 40mg, 80mg — confirmed via FDA ANDA 206511 final approval, with bioequivalence to Micardis established for all three strengths . Also confirmed for telmisartan/hydrochlorothiazide combinations. Market scope: US ANDA confirmed (ANDA 206511); Indian domestic market.
∙ Quality Rationale: One of India’s largest generics manufacturers by ANDA volume, with over 400 final FDA approvals. Vertically integrated via Apitoria Pharma (API subsidiary). Substantial scale and quality infrastructure investment. US formulation revenue exceeds $1.5B annually.
∙ Compliance Note: January 2022 Warning Letter to the API facility in Telangana for failure to evaluate manufacturing change impacts on API quality and failure to investigate critical deviations . The 2022 Warning Letter was formally closed by the FDA in late 2025 following a for-cause re-inspection in August 2025 that itself generated a five-observation Form 483, subsequently resolved . Closure is positive, but the pattern of requiring a for-cause re-inspection with new observations before resolution is a meaningful signal about the facility’s quality culture over this period. A 2024 Class I recall for an OTC product involved a missing label — administrative, not chemical quality failure, low relevance to telmisartan.
∙ Standout Factor (Negative): API facility Warning Letter (2022, closed 2025) with for-cause re-inspection pattern warrants downweighting for an ARB specifically. Ranks below Macleods on this basis despite larger overall footprint.
Option 4: Cresar / Teleact — Cipla Limited / Sun Pharma Laboratories
These are addressed together because they share a similar compliance profile and the same fundamental problem: both companies carry active or recently active Warning Letters across multiple Indian manufacturing sites.
Cresar (Cipla): Cresar (20mg, 40mg, 80mg) is manufactured by Cipla Limited . Cipla’s Pithampur facility received a November 2023 Warning Letter for CGMP violations including failure to submit Field Alert Reports, with the FDA explicitly noting similar violations had been cited at Cipla’s Goa facility in 2020 and again in 2022 — demonstrating systemic multi-site quality management issues . US ANDA confirmed for telmisartan. Ranked fourth due to multi-site repeat violation pattern.
Teleact (Sun Pharma): Teleact (20mg, 40mg) is manufactured by Sun Pharma Laboratories Ltd.  — confirmed via PharmEasy product listing. Sun Pharma’s Halol, Gujarat facility received a Warning Letter in October 2023 for significant CGMP violations including metallic particle contamination in injectables, inadequate equipment maintenance, and failure to comprehensively investigate deviations . A second Warning Letter was issued in June 2024 for Sun’s Dadra facility following OAI classification after a December 2023 inspection , and a July 2025 inspection of Sun’s Gujarat plant generated a 19-observation Form 483 with repeat findings from the 2022 Warning Letter . Two Warning Letters across two facilities plus repeat 2025 observations is a disqualifying pattern for top ranking despite Sun’s scale. Teleact is a solid Indian-market brand from a highly credible company, but the current compliance picture does not support ranking it above the options above. Market scope: Indian domestic market; Sun Pharma does hold US ANDA for generic telmisartan but under a different label.
Executive Summary
| Compound | Rank | Brand | Manufacturer | Dosages | Market Scope | Flags |
|---|---|---|---|---|---|---|
| Telmisartan | 1 | Telpres | Abbott India / Abbott Healthcare | 40mg, 80mg confirmed; 20mg unverified |
|
|
| Telmisartan | 2 | Telmisartan USP | Macleods Pharmaceuticals | 20mg, 40mg, 80mg |
|
|
| Telmisartan | 3 | Telmisartan USP | Aurobindo Pharma | 20mg, 40mg, 80mg |
|
|
| Telmisartan | 4 | Cresar | Cipla | 20mg, 40mg, 80mg |
|
|
| Telmisartan | 4 | Teleact | Sun Pharma Laboratories | 20mg, 40mg |
|
|
1 Like
This is consistent with the recommendations of the frequent buyers on meso-rx where they frequently order from India and have come up with commonly referenced “gold standard” brands. It also matches with my recent order of Telmi from India: requested Telpres but didn’t hav access to it without near expiration dates so ended up with Cresar and happy with that too.
1 Like
That prompt and the results seem pretty good. This seems like the easiest and fastest way to identify the brands you can “reasonably” trust.
1 Like
Something new I’m playing with these days…
find a lecture on youtube
get transcript from http://ytscribe.ai
paste it into gemini with this prompt:
Generate an image. Turn this transcript into a cheatsheet with key takeaways, and give final output as 9:16 image created by nano banana.
Example:
Video:

Result:
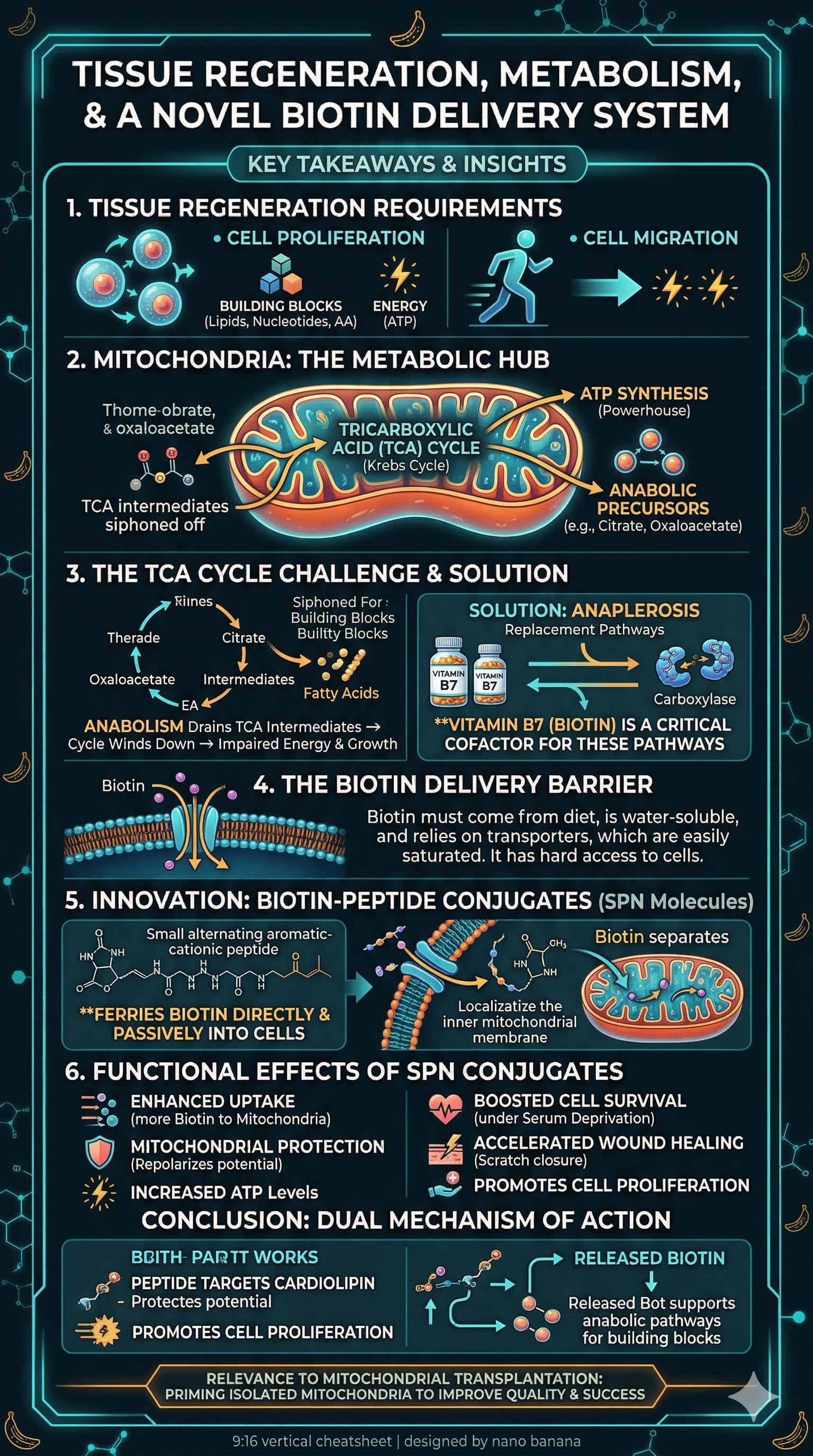
Example 2
Video:

Result:
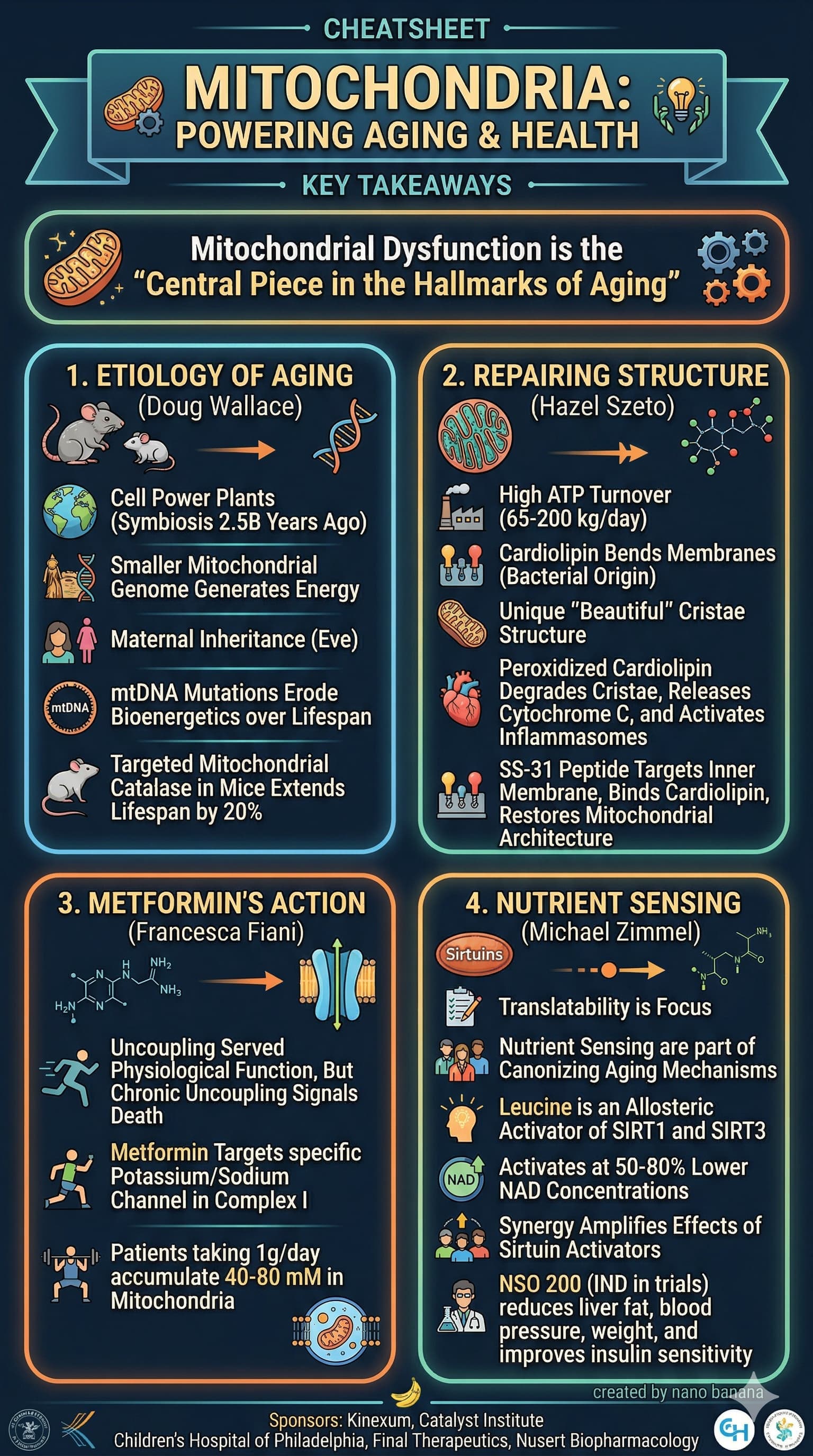
3 Likes