5/8/25 Update to clarify that markdown output has to be chunked just like plain text.
Here’s how I do it.
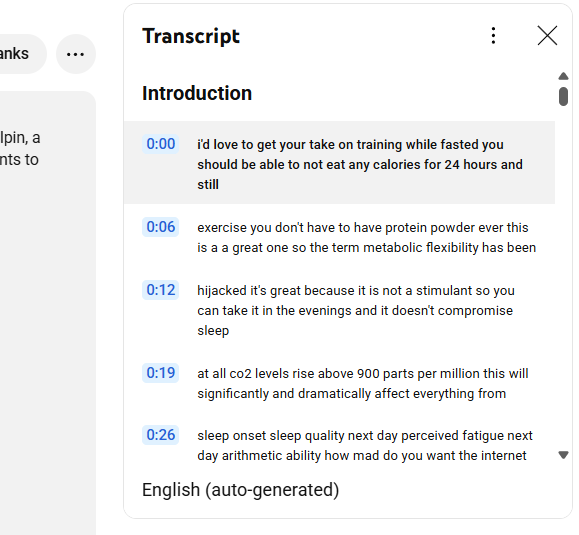
1. Extract the transcript using youtube-transcript.io. Input the video url, get the extracted transcript after a few seconds. Click the three dots next to ‘copy transcript’ and select ‘download’, see some options which I don’t touch, and save as text file.
This particular website has a limit of 25 free extractions. Once I run out of free, I may look for always free. Anyway, it works for now.

2. a. Upload the text file to Grok. A verified X account is required to upload files.
b. Also upload the following quoted text as a text file. There is some unneeded stuff in there that I thought I had cleaned up, but it should work as is.
Generalized Rules for Formatting Podcast Transcripts
Content Handling:
- Provide a verbatim transcript, preserving exact dialogue, including errors and colloquialisms (e.g., “Geez,” “right?”).
- Do not summarize or omit any content; include the full duration of the transcript.
- Insert commas into sentences as needed, per grammatical rules, to enhance readability.
- Split the transcript into two chunks to manage output length, unless otherwise specified:
- Chunk 1: From 00:00 to approximately [CHUNK1_END] (e.g., 45:00), ending at a natural break point after a speaker’s complete statement.
- Chunk 2: From [CHUNK1_END] to [DURATION], continuing seamlessly.
- Specify [CHUNK1_END] per transcript, targeting ~45 minutes unless otherwise directed.
- Remove fillers (“um,” “uh,” “you know,” etc.) from all dialogue.
- Correct any scientific terms identified as errors, (e.g., “bereiement” to “bereavement,” “thenologists” to “thanatologists”). If none, note no corrections needed.
- Flag potential speaker mis-identifications in a note, confirming correct attribution for speakers, specified as [SPEAKER_NAMES] (e.g., Speaker1 (Interviewer), Speaker2 (Guest)). Verify roles and note if no mis-identifications are detected.
Formatting Structure:
- Combine all sentences in a single response per speaker turn, preserving the original dialogue flow without splitting into individual statements.
- Bold all speaker names, specified as [SPEAKER_NAMES], using appropriate syntax:
- In plain text or word processors, apply bold formatting (e.g., Speaker1).
- In Markdown, use double asterisks (e.g., Speaker1:).
- Insert timestamps every ~5 minutes, aligned with original transcript timing (e.g., [00:00], [05:00]), on their own line with no extra spacing before or after the following speaker.
- Double space after each speaker’s response by adding two blank lines (in Markdown, two line breaks).
- Include header information at the top:
- Title: [TITLE] (e.g., “Podcast Episode Title”), to be specified per transcript.
- Speakers: [SPEAKER_NAMES] with roles (e.g., Speaker1 (Interviewer), Speaker2 (Guest)).
- Total transcript duration.
- Note: Summarize formatting details, including fillers removed, scientific terms corrected (list [SCIENTIFIC_TERMS] or note none), no speaker mis-identifications (or list flags), timestamps every ~5 minutes, bold speaker names, and double spacing.
Output Specifications:
- Output the first 45 minutes in plain text for review, with bolded speaker names and double spacing applied in word processors or PDF editors. Pause for review and possible further instructions.
- Provide final output in Markdown format for PDF conversion, using:
- Double asterisks for bold speaker names (e.g., Speaker1:).
- Two line breaks for double spacing after each response.
- Plain text for timestamps and dialogue.
- Support PDF conversion with a target font size of 16-point for body text:
- Use Pandoc with a CSS file specifying:
- body: font-family: Arial, sans-serif; font-size: 16pt; line-height: 1.5; margin: 1in.
- h1 (title): font-size: 20pt; font-weight: bold.
- p: margin-bottom: 1em.
- strong: font-weight: bold.
- Alternatively, format in Google Docs with Arial, 16 pt font, then export to PDF.
- Ensure compatibility with PDF Viewer Plus (Windows) for annotations, where added text (e.g., comments, text boxes) can be set to 16-point font via the Properties toolbar.
Additional Notes:
- Preserve the transcript’s structure for PDF output, ensuring readability with 14-point font, bold speaker names, and double spacing.
- Support Markdown-to-PDF conversion using Google Docs.
- Verify output for consistency: bold speaker names, double spacing, and accurate timestamps.
- Allow customization per transcript for:
- [TITLE]: Episode title.
- [SPEAKER_NAMES]: List of speakers and roles.
- [CHUNK1_END]: Break point for Chunk 1 (e.g., 45:00).
- [SCIENTIFIC_TERMS]: Terms to correct, if any.
3. So now you’ve attached two files to your empty prompt. Here is a sample prompt text:
Attached is a youtube transcript. also attached are generalized formatting rules for the transcript. Particular to this transcript, the host is Jim, and the guest is Karen. Since there are some very large blocks of single speaker conversation just add a timestamp every 15 minutes or so. Please proceed to follow the uploaded instructions, combined with the customization I’ve specified here, output the first 30 minutes of the result in plain text, and then pause for further instructions.
Sample result from the above generalized and tailored instructions:
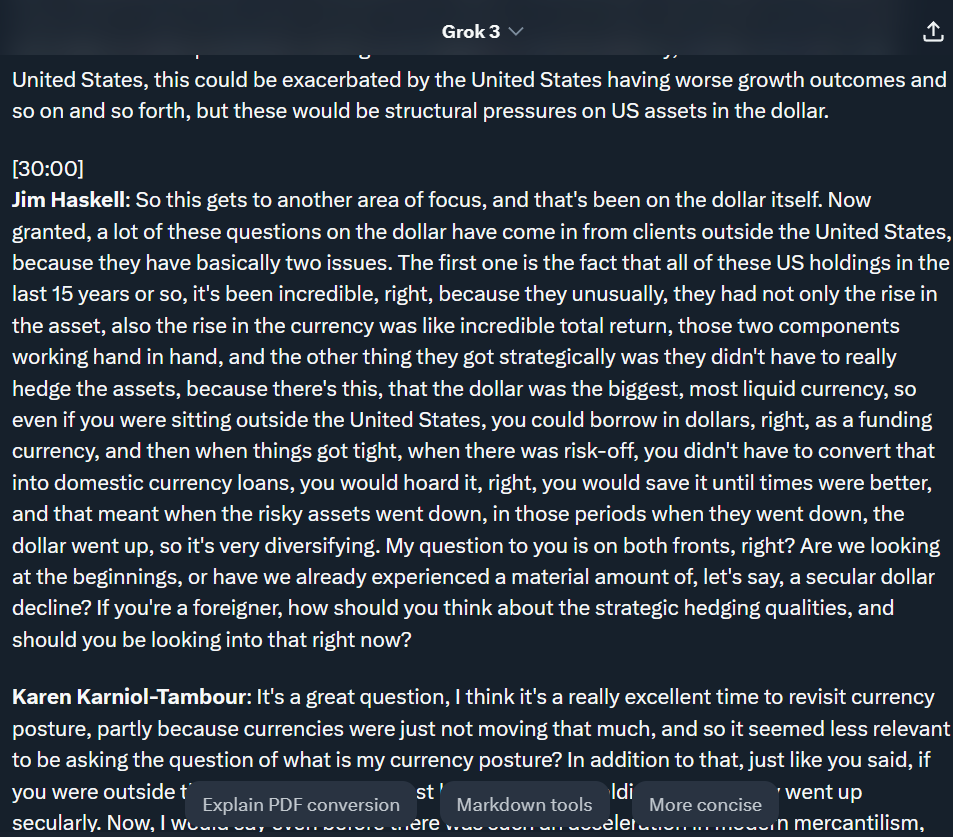
Note that I specified just Jim and Karen as the speakers, but Grok decided full names would be more appropriate. One needs to scroll through the first few minutes of output (you can tell grok to output the first 30 minutes, and then pause), and determine jus how closely the rulles were followed. If something is off, just tell grok what it is, and request to regenerate.
Note that grok will lock up after about 60 minutes of continuous plain text output, so that’s why 45-minute chunks are requested in the generalized instructions.
If it all looks good in plain text, then ask grok for a markdown file. Tell grok chunks aren’t necessary for the .md file, one continuous stream is fine. Update: Yes, you do need to chunk markdown, just like plain text. Also, when requesting markdown, ask for ‘markdown code block’.
Output looks like this:

4. Click on the ‘copy’ button underlined above. Open a new text file. Paste what you copied. Click ‘save as’ then then create a file name ending in .md. (Will have to change to ‘all files’ over on the bottom right.)
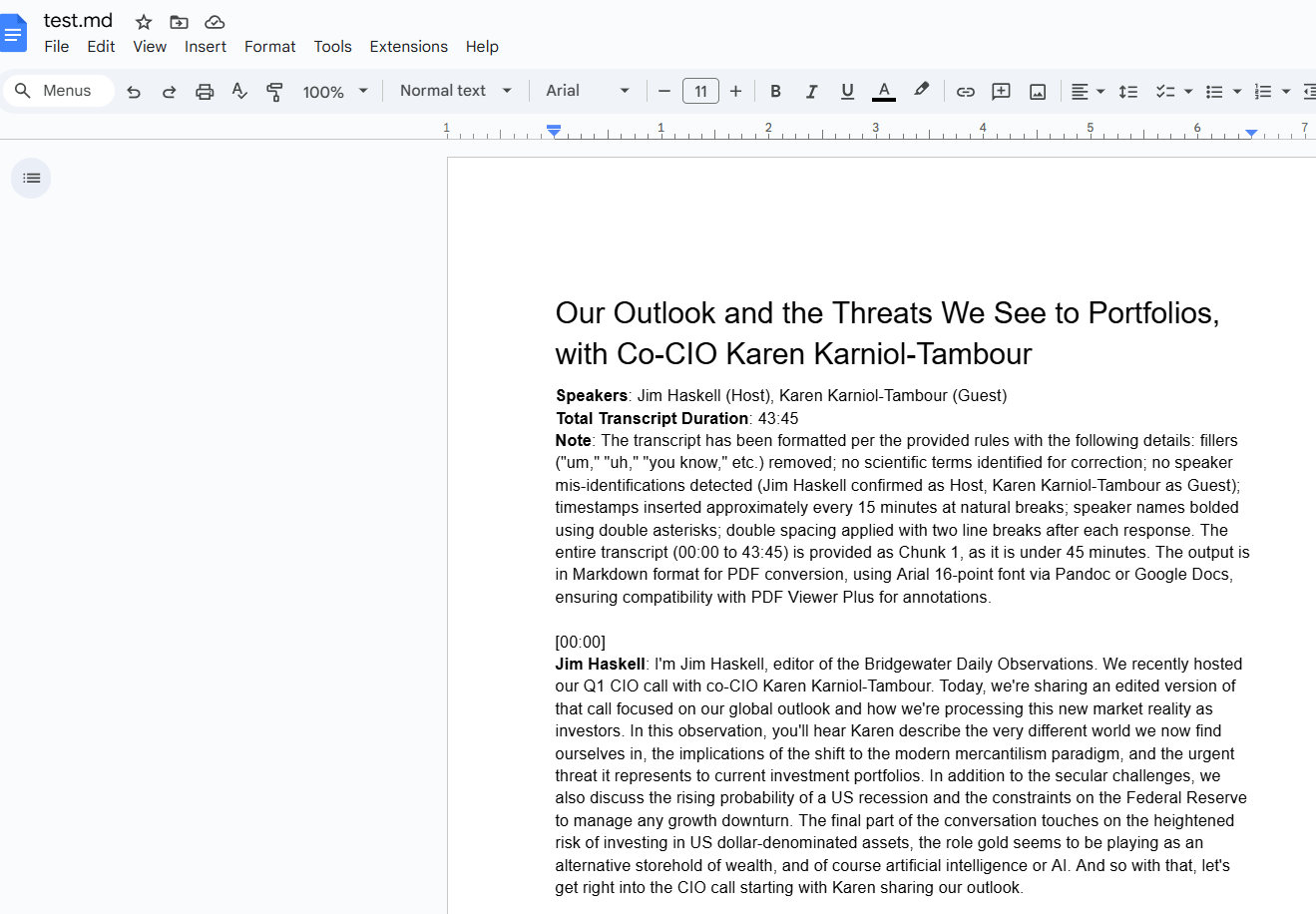
5. Create a new empty google doc, click ‘open’ under ‘file’, then ‘upload’, and select the .md file.
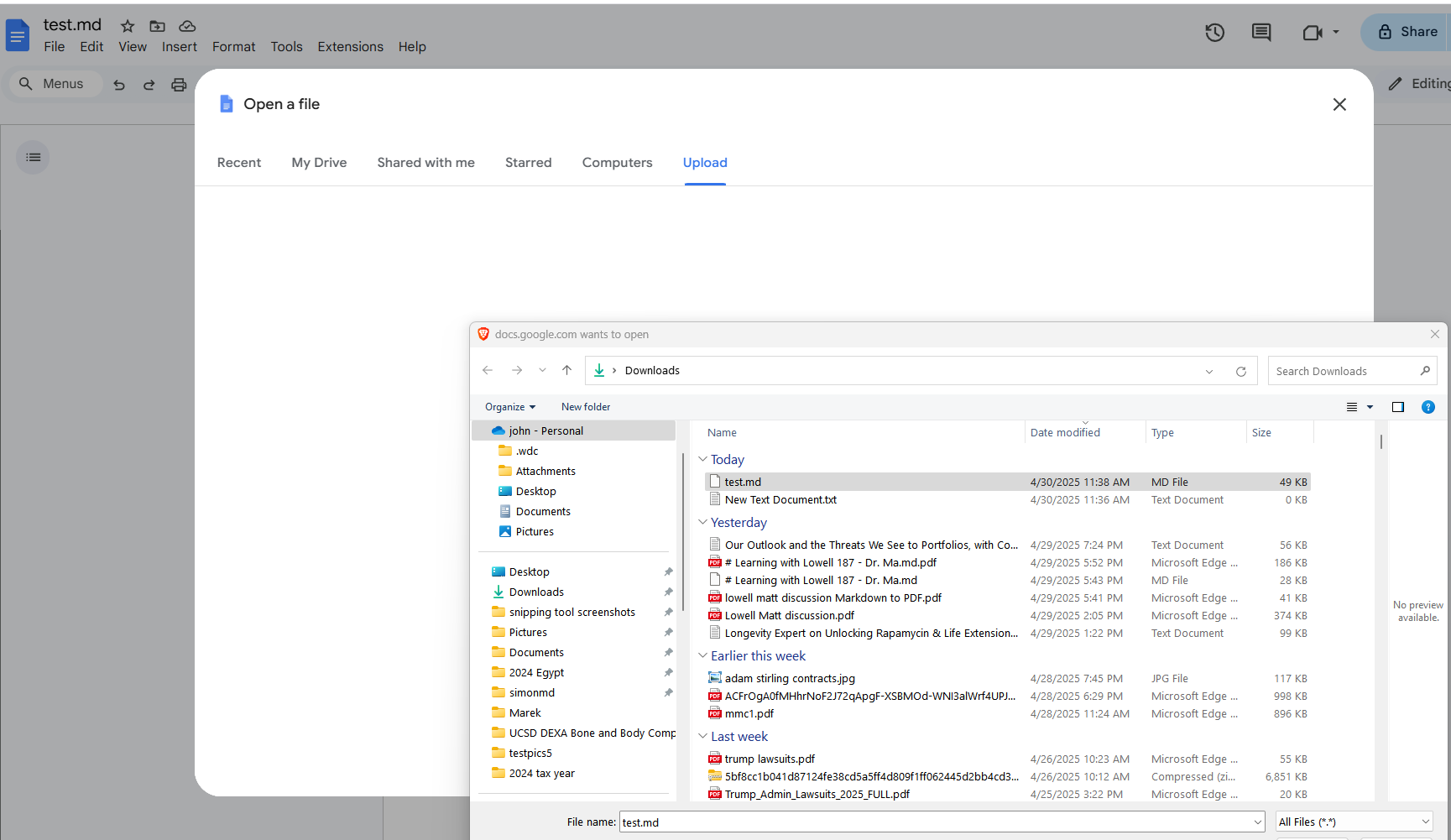
Should see title and speakers bolded, etc,:
6. Next, ‘file’ ->‘download’->PDF. And the result:
test.md.pdf (268.3 KB)
Additional comments:
More than two speakers - Grok seems able to fairly accurately group complete comments by a single speaker. And if there’s just two speakers, it can keep straight who is the host/guest. I converted a transcript with three speakers, and I told groc the host was xxxx and that it could just label other speakers as ‘speaker’. Perhaps saying ‘just figure it out on your own’ would work, haven’t tried. I converted a five speaker, 3+ hour roundtable with everyone labeled ‘speaker’, and it seemed comprehensible despite not knowing who exactly was talking.
Using other AI’s - Initially I tried 4o and it couldn’t cope. I also tried one other, I think it was deepseek, same results. But you can try the above inputs and see if you have better luck.