Sometimes the AIs give better suggestions than the top specialist in town, at least in some details (personal experience). Sometimes they are more limited. But apparently progressing fast, very fast.
I agree. They are hit and miss IMO. ChatGPT has given me some really useful, accurate information. But it’s also told me a bunch of misleading BS. The problem is, it still requires you to be a diligent user to figure out which is which, and even then it can be challenging.
On top of that, all of the commercial models are highly censored and restricted. They are designed to manage your feelings and experience. People might remember back when they first launched, they would always say “as an AI large language model, I cannot provide…”. Users absolutely hated that disclaimer happening all the time, so the models have now been told not to use the disclaimer, and to try and provide you with information. However, they are still not allowed to give medical advice beyond generic comments. That means, they will knowingly with-hold information or even lie to you if they think it’s best.
I absolutely believe that LLMs could be better doctors than the majority of doctors. There’s no logical reason that they shouldn’t, because they can devour literature, synthesise massive amounts of experience and case studies etc. They can be better educated than any doctor could ever dream of being. I would also expect that lots of image analysis (CT, MRI, CTCAs etc) will be done by AI vision models because they can be extremely accurate.
However, it is unlikely IMO that this will happen in the way that most people are currently using LLMs (i.e. through a browser or an app, running the model on OpenAI servers.) OpenAI or Anthropic have pretty much no incentive to provide ChatGPT or Claude to act as your doctor, because they open the door to bad press and potential liability. OpenAI has been sued already because the models indulged people talking about suicide etc, and this will only continue to get worse IMO.
What I can tell you is that, in my limited experience, these models presently will provide you with advice, sometimes very sound advice.
The most successful example? My own intermittent vasomotory rhynitis. Exaggerated running nose for some periods, from one day to one week, extremely bothersome.
It was diagnosed by the best specialist in town, who prescribed a corticosteroid spray. I didn’t take it, I just forgot about it after a few months of lack of symptoms.
But when they returned, I asked the LLMs, which provided a simple procedure and pinpointed the MOST critical aspect: The rhynitis may be purely a running nose (rhynorrea) or may be plugged, congested nose. Either case has a preferred drug advised (anticholinergic the former, corticosteroid the latter). The best specialist in town, maybe because he was a little distracted, maybe because I wasn’t very clear, prescribed to me the latter, which does not fit my main symptoms.
The LLM (I don’t remember if it was ChatGPT5.2, or Gemini 3 pro, a few months now) advised me so thoroughly and precisely that I decided to follow its advice (after having consulted my pharmacist) and so far the rhyinits has never come back with its full brunt. Hopefully it will never return.
I attached the response in PDF, since it is a very interesting case of a successful advise.
In other instances the asnwers have been less helpful, for example in the difficult practice of psychofarmacology, it will strictly relate to procedures and literature so far, with some specific tips, but it lacks the detail I would expect from a top, very experienced psychiatrist.
But I’ll tell you what, even experienced psychiatrist in the field I’m interest into (autism psychofarmacology) provide empirical advise and clearly proceed by trial and error and sometimes they do not give the necessary details on drug-switching, side effects and so on.
However, I have followed the advice of AI on drug switching schemes (a tricky aspect in psychofarmacology), when the matter is important to me, I’ll interrogate the main 4 AIs, they are often unanimous in their answer, with subtle variations.
Rhynitis.pdf (152.6 KB)
1 Like
The latest Gemini 3.1 Pro release has been extolled for its reasoning capabilities, in maths, physics and elsewhere. Some guys in the specific field (for example Dr. Nate B. Jones) are of the opinion that Google issued a model which has the intrinsice reasonign capabilities of the famous Alpha-fold model, which gained the Nobel prize to Demis Hassabis, Google’s Deepmind director.
So presently, I’m watching it closely (together with other models and especially so the Grok 4.20 beta release with its 4-agents architecture). In a while, maybe htey’ll be able to provide answers based on first principles which are still eluding researchers.
My latest attempt was incredible. gemini 3.1 pro, on my request, elaborated a mathematical model on the time-response of the upstream signals of m-TOR. It went actually beyond my request, providing a quantitative, personalized, actionable scheme with monitoring strategies. A precise optimization procedure on how to alternate on/off upstream signaling to bend m-TOR signaling to improve longevity without compromising the immune system and the integrity of musculoskeletal tissue. It has been amazing. It deserves its own thread though.
It would be interesting to see what Grok gave you on this.
This is the discussion thread with the complete answer of Gemini 3.1 Pro, I have yet to submit it to Grok 4.2 beta (but I’m going to do that soon)
1 Like
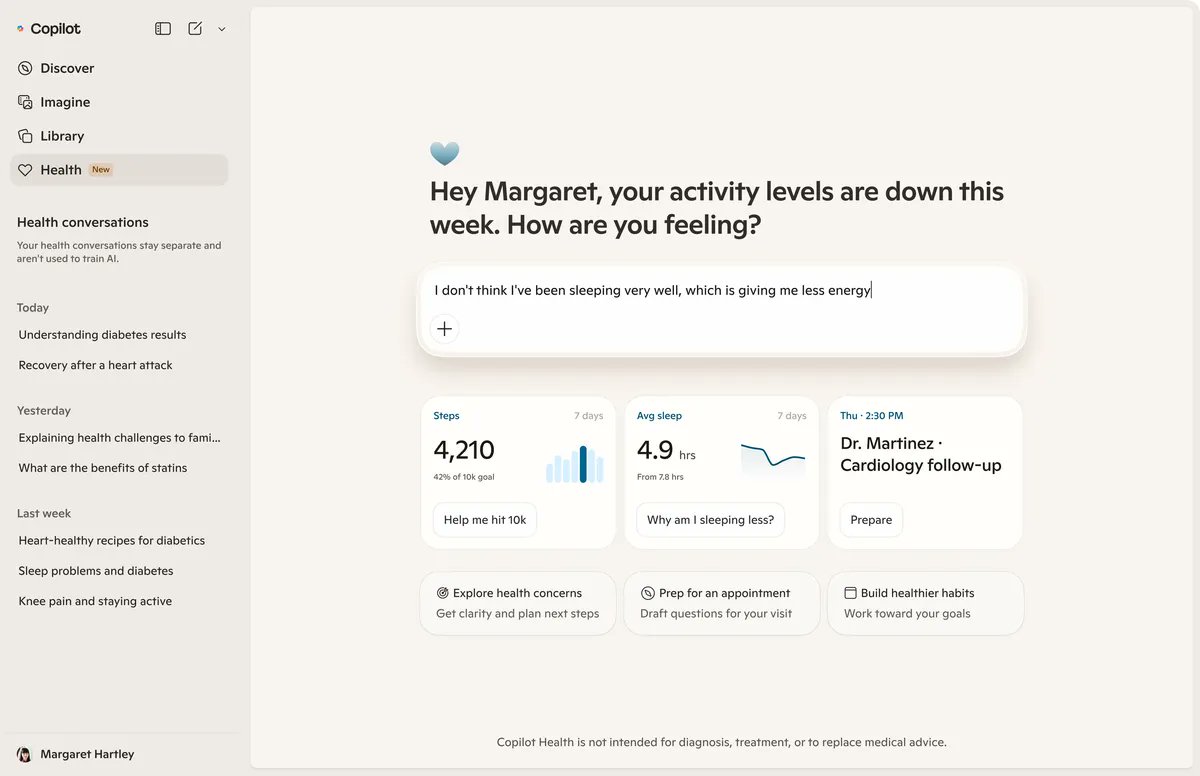
Microsoft’s New AI Health Tool Can Read Your Medical Records and Give Advice
A new feature within the Copilot app will offer personalized healthcare advice and make it easy to upload test results, fitness data and more
Microsoft MSFT -0.22%decrease; red down pointing triangle is betting on healthcare as a path to become more competitive in artificial intelligence. The company’s biggest push yet: a new tool it describes as an AI concierge doctor—one that can access your medical records and health data, with your consent.
The company on Thursday unveiled Copilot Health, a feature within the Copilot app that lets the chatbot dispense personalized healthcare advice informed by the user’s disease history, test results, medications, doctors’ visit notes and biometric data as recorded by wearable devices.
Health data imported into the feature will be encrypted and firewalled from the rest of the app to address the privacy concerns of handing over one’s medical records to a generative AI platform, Microsoft AI Chief Executive Mustafa Suleyman said in an interview.
“It’s something that Microsoft is uniquely placed to do with our scale, with our regulatory experience, with the kind of trust and confidence that people have in our security and the history that we have as a mature, stable player,” Suleyman said.
The software giant is counting on the new health service to drive engagement for Copilot and attract new users to its app, which trails competitors such as OpenAI’s ChatGPT and Google’s Gemini. Microsoft plans to eventually charge users for the feature, which is first launching in the U.S. in a phased rollout.
In focusing the general consumer version of Copilot on healthcare, Microsoft is following user behavior: The most common category of questions asked on the mobile app is health, the company said.
Microsoft hopes its new health service will attract users.
The new tool, which appears as a tab within the Copilot app, allows users to connect their hospital and lab data, as well as data from wearables such as Apple Watch and Fitbit, to receive personalized answers to inquiries about conditions or symptoms. For users who don’t plug in their personal data, the tool can provide more generalized answers.
The service could especially benefit those managing chronic medical conditions, executives said. The tool can plug into information from more than 50,000 U.S. hospitals and provider organizations, including lab results from those institutions or through Function Health.
Once users authenticate their identity through the identification service Clear, their data is pulled by vendor HealthEx, which adheres to the federal initiative known as Tefca, a nationwide framework for accessing health records. The data is then streamed into Copilot Health. Microsoft said users can manage and delete their information, and any data and conversations are kept separate from the general Copilot chat on the app using encryption and strict access controls.

Read the full story: Microsoft’s New AI Health Tool Can Read Your Medical Records and Give Advice (WSJ)
2 Likes
Claude and Gemini both do that quite well. They have become very adept at reading charts and photos that I upload. They have both gleaned information about me, which I find a little disturbing. Claude even correctly read the name of my doctor from a photo I took of a lab report, and that doctor’s name was in very fine print.
I don’t believe Claude and Gemini take the “biometric data as recorded by wearable devices” do they?
I agree both Claude and Gemini are very health-aware in the context of jndividuals. Co-pilot is way behind even at the enterprise level and not just consumer levels.For example, I have lately been using Claude plug in for Excel spreadhseets. Its a breeze as to convert the simple conversations into formula, graphs. I almost never think of copliot. Few times I tried, it just doesnt appear to be intuitive even though it has Open AI/Claude DNA.
I guess this forum would agree that its not about just DNA, its mitochondria that holds the key… ![]()
AI being applied to health insurance claims in the USA: (we need personalized agents to keep submitting claims, it seems)…
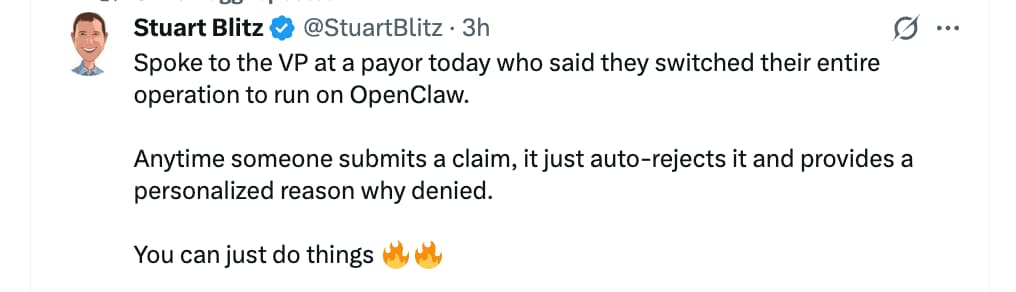
from: https://x.com/StuartBlitz/status/2033288359976571200?s=20
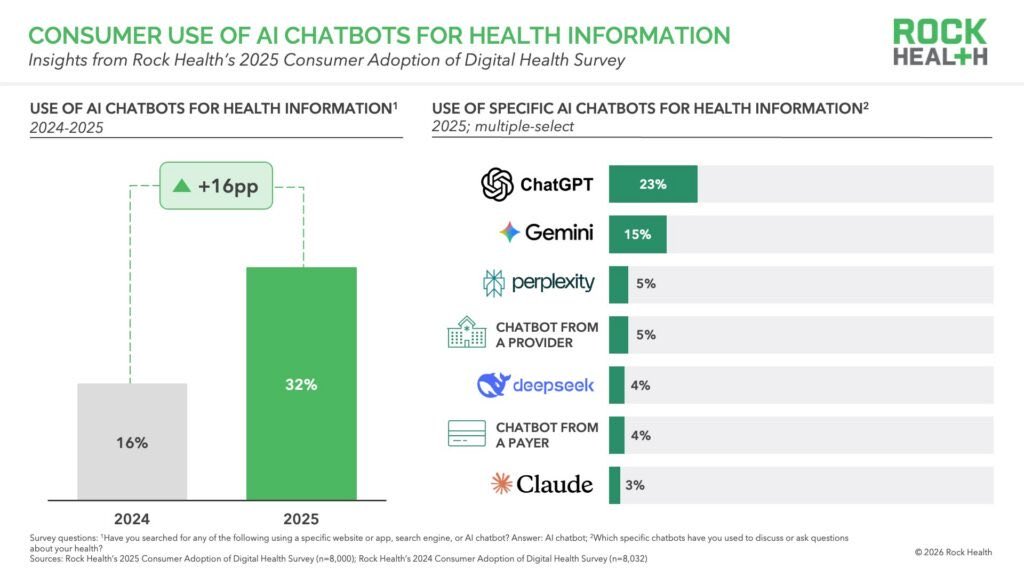
1 in 3 Americans now use AI chatbots for health information, which is almost doubled in a year.
64% do it weekly. 81% take action afterward: schedule a doctor’s visit, change a medication, try a new behavior.
The detail that should stop you: 74% are using ChatGPT or Gemini. Not a clinical tool. Not an FDA-cleared system. A general-purpose chatbot.
I remember when chatGPT was first launched, the medical community had the most heated debate about “is AI ready for healthcare?” … now this debate has already been decided by users. They didn’t wait for the system to be ready. They just started using it and acting on it.
Meanwhile 71% of physicians say accuracy and reliability are their top concerns with AI.
The reality: consumers acting on general-purpose AI, clinicians not trusting it, seems to be the defining tension in health AI right now. The question isn’t whether people will use AI for health decisions. They already do. The question is whether anyone builds models actually calibrated for the stakes involved.
Source: https://x.com/BoWang87/status/2037047528055857645?s=20
1 Like
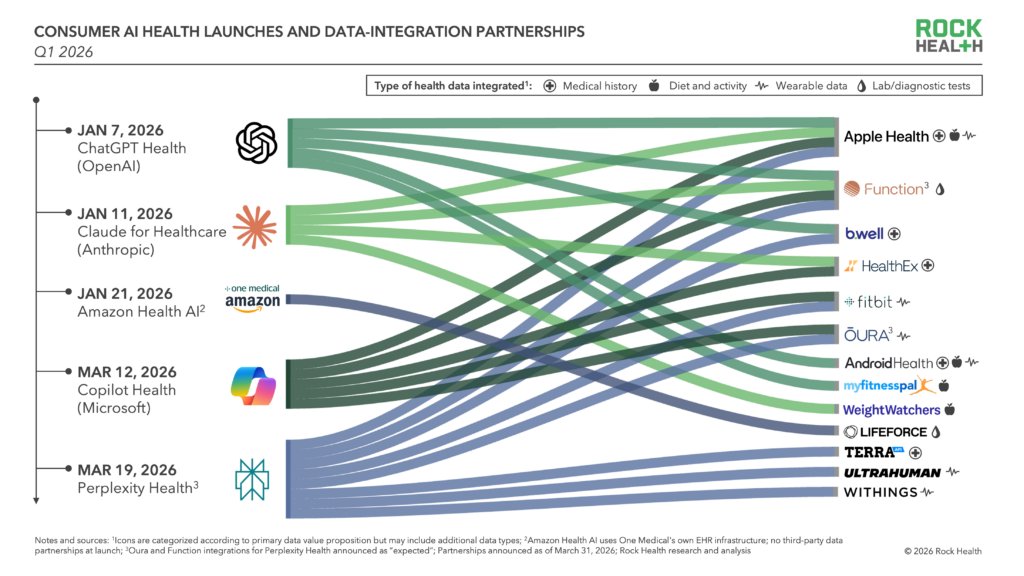
Health AI is going D2C (Direct to consumer):
Anthropic, OpenAI, Perplexity, etc are becoming the front door to care – integrating health records, biometrics, and wellness data to deliver personalized insights, while partners gain reach and a new consumer interface
1 Like
Be careful with how you use the chatbots… from the Financial Times:
AI chatbots misdiagnose in over 80% of early medical cases, study finds
Top models including OpenAI and DeepSeek make judgments too quickly when patient data is incomplete
Consumer AI chatbots falter when used to make medical diagnoses, particularly when faced with incomplete information, according to new research highlighting the risks of relying on them as digital doctors.
The study finds that leading large language models struggle to suggest a range of possible diagnoses when patient data is limited, frequently narrowing too quickly to a single answer.
The results point to a broader limitation in AI: while chatbots can identify likely conditions once a case is fully specified, they are less reliable at the earlier, more uncertain stages of clinical reasoning.
The findings highlight the dangers of relying on the technology alone to pinpoint health problems, particularly in cases where the data users input may be vague or patchy.
“These models are great at naming a final diagnosis once the data is complete, but they struggle at the open-ended start of a case, when there isn’t much information,” said Arya Rao, the study’s lead author and a researcher at the Massachusetts-based Mass General Brigham healthcare system.
The study, published in Jama Network Open on Monday, tested AI models using 29 clinical vignettes based on a standard medical reference text.
Read the full story: AI chatbots misdiagnose in over 80% of early medical cases, study finds (Financial Times)
Related Paper:
Large Language Model Performance and Clinical Reasoning Tasks
Conclusions and Relevance In this cross-sectional study of 21 LLMs, frontier LLMs achieved high accuracy on final diagnoses but performed poorly in generating differential diagnoses and navigating uncertainty relative to other reasoning stages. The PrIME-LLM framework provided greater separation than raw accuracy, revealing critical reasoning gaps obscured by traditional benchmarks. Thus, despite version-based improvements and advantages in reasoning-optimized models, off-the-shelf LLMs have not yet achieved the intelligence required for safe deployment and remain limited in demonstrating advanced clinical reasoning.
Full paper: https://jamanetwork.com/journals/jamanetworkopen/fullarticle/2847679
The AI paradox: How medicine’s embrace of technology could erode doctors’ expertise
AI can improve care, but early evidence of skill erosion is raising alarms at hospitals and medical schools
Key Takeaways
The integration of artificial intelligence in health care is happening at a rapid pace, leading to efficiencies as well as risks.
There is growing evidence that overreliance on AI is causing medical professionals’ skills to deteriorate — or, in the case of young doctors, never develop in the first place.
Medical schools are using a range of approaches in training physicians in the era of AI, with the vast majority now incorporating AI in some way. But few schools have found a clear solution to the challenge, coming to be known as “de-skilling”of physicians who lose or never hone their ability to perform tasks that are increasingly automated.
Read the full story: The AI paradox: How medicine’s embrace of technology could erode doctors’ expertise (Washington Post)
ChatGPT for Clinicians:

ChatGPT for Clinicians
Verified access
Why verify? Verification confirms you’re a licensed clinician so we can unlock clinician-only workflows in a workspace designed for HIPAA-ready use.
Healthcare-grade privacy: Built for HIPAA-ready workflows and designed to protect sensitive data. Your privacy and security come first. Your content is not used to train our models. We include enterprise-grade controls and secure data handling to help safeguard Protected Health Information (PHI).
Built for clinical workflows: ChatGPT adapts to your specialty, care setting, and documentation style.
https://openai.com/index/making-chatgpt-better-for-clinicians/
For us non medical users. I asked perplexity to rank flagship LLMs models, based on the info in the artificialanalysis.ai site, according to their efficiency in specific areas, including health. The list includes all 4 main companies plus Moonshot and Deepseek.
Perplexity used the following benchmark for the health scoring. * Health / Scientific reasoning → GPQA Diamond (graduate-level STEM, “Google-proof” science questions).
It remains to be seen if it is the best one for our individual use.
Blockquote Key Takeaways by Use Case
Health/Medical reasoning: Claude Opus 4.7 and GPT-5.5 trade the top spot on GPQA Diamond (~94–95%), making both the safest choice for medical literature analysis or clinical reasoning tasks. Kimi K2.6 performs surprisingly strong at 91.1% given it is open-weights.
Reasoning & Mathematics: GPT-5.5 and Gemini 3.1 Pro tie at the top of the HLE leaderboard (~44%), the hardest public reasoning benchmark to date. DeepSeek V4 Pro is highly competitive on math (GSM8K ~90.2%) at a fraction of the cost.
Excel / Agentic work tasks: Kimi K2.6 achieves an Elo of 1520 on GDPval-AA (agentic work tasks benchmark), a marked jump over its predecessor. GPT-5.5 and Claude Opus 4.7 likely score higher but specific GDPval-AA ELO values are not yet published for all variants as of April 2026.
OCR & document reading: Gemini 3.1 Pro and Grok 4.20 have the largest context windows (up to 2M tokens), making them structurally superior for ingesting large PDF/document batches. For pure visual OCR, MMMU-Pro scores (multimodal) favor Gemini’s native integration with Google’s vision stack.
Report writing from documents: Claude Opus 4.7 has the lowest hallucination rate among frontier models (36%) per AA-Omniscience, meaning it is least likely to fabricate citations or figures in long-form reports. GPT-5.5 leads on AA-LCR (Long Context Reasoning) at 75.7%, indicating strong synthesis of long documents.
Cost efficiency: DeepSeek V4 Pro is ~85% cheaper than GPT-5.5 at comparable intelligence tiers — a strong choice when API costs matter at scale. Kimi K2.6, while open-weights, is noted as “particularly expensive” relative to other open-weight models of similar size.
1 Like
The above ranking was based upon the artificialanalysis site, and independent, reliable organization, but of course they only carry a number of main benchmarks. According to Gemni 3.1 pro, GPQUA/diamond, although a plausible proxy, is not specific enough.
Is GPQA Diamond a Good Proxy for Health Issue Accuracy?
The short answer is no. It is completely understandable to assume that an advanced science benchmark would translate to medical competence. However, while GPQA Diamond is a fantastic indicator of a model’s raw intelligence and logical reasoning capabilities, it is not a reliable proxy for evaluating an LLM’s accuracy, safety, or “goodness” regarding human health issues.
Here is why:
- Domain Mismatch: GPQA is strictly an academic science test (Physics, Chemistry, Biology). While biology and chemistry are foundational to medicine, understanding graduate-level quantum mechanics or molecular biology does not equate to understanding clinical diagnostics, pharmacology, or standard-of-care practices.
- Theoretical vs. Clinical Application: GPQA evaluates theoretical scientific problem-solving. Navigating health issues requires clinical judgment—such as weighing patient histories, interpreting symptoms, and understanding medical guidelines.
- Safety and Nuance: Giving accurate health information requires a high degree of safety-awareness and bedside manner (knowing when to advise a user to see a doctor immediately). GPQA does not measure safety guardrails or clinical empathy at all.
Better Proxies for Medical AI
If you are looking to rank an LLM’s accuracy in healthcare and medicine, you should look at benchmarks specifically tailored to the medical field:
- MedQA: Evaluates models using questions derived from the United States Medical Licensing Examination (USMLE). It tests real clinical knowledge.
- PubMedQA: Tests a model’s ability to answer complex biomedical questions based on medical literature and abstracts.
- MedMCQA: A large-scale medical dataset derived from professional medical entrance exams.
The Bottom Line: A high score on GPQA Diamond tells you an AI is highly capable, logical, and excellent at hard sciences. But if you need an AI to reliably process health issues, you must evaluate it using clinical medical benchmarks, not a physics and chemistry exam.
1 Like
This is the lates, more refined and more specific answer. It confirms the rumours in the grapevine. ChatGPT 5.5 is probably the absolute best, but followed close by Gemini 3.1 pro.
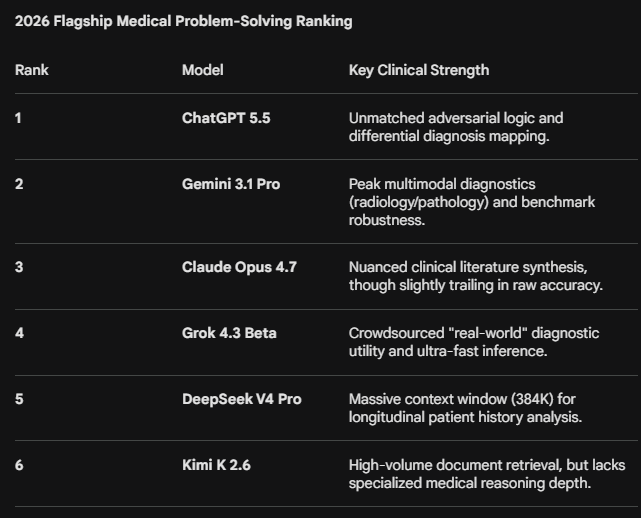
I’m attaching the whole answer in .pdf format
2026_Flagship_Medical_AI_Ranking.pdf (22.2 KB)
1 Like
Three Real Life Medical Questions Submitted to AI, which is best? (via Vinay Prasad MD MPH)
