HT BENGIO
An achievement combining the work of people at Google Deepmind and some mathematicians:
https://x.com/A_G_I_Joe/status/2011213692617285729#m
New paper out today, proving a novel theorem in algebraic geometry with an internal math-specialized version of Gemini. This was a collaboration between @GoogleDeepMind (Professor Freddie Manners and @GSalafatinos, hosted by the Blueshift team) and Professors Jim Bryan, Balazs Elek, and Ravi Vakil.
Ravi Vakil, a world-class mathematician at Stanford said:
As someone familiar with the literature, I found that Gemini’s argument was no mere repackaging of existing proofs; it was the kind of insight I would have been proud to produce myself. While I might have eventually reached this conclusion on my own, I cannot say so with certainty.
A Cambridge undergrad wrote a tweet about how he thought the Gemini models used might have just done some elementary “sum switching” and didn’t do any hard algebraic geometry, but then one of the authors of the paper corrected him and he (the Cambridge undergrad) deleted it:
https://xcancel.com/GSalafatinos/status/2011539686389416313#m
No, the model did algebraic geometry work too. The reason much of it isn’t included is because the authors could intuit most of the algebraic geometry just with the small case results and decided to write it by hand rather than precisely copy/verify every detail of the output
So, it seems models are now able to produce “novel ideas” that didn’t appear in the literature elsewhere – not mere repackaging of existing ideas, but truly novel ideas. Indeed, they write in the paper:
It is natural to ask how close the resemblance is between the AI-contributed proofs, and
prior literature that Gemini is likely to have seen in its training data [As run, none of the systems had access to the internet or other search tools.]. Certainly the latter
includes related work such as [1, 3], and it seems likely that being able to build on these
arguments made the problem more tractable for the AI systems than some other research problems. However, the model outputs (such as the one in Appendix C) do not appear to
the authors to be that close to those or (to the best of our knowledge) any other pre-existing
sources. So, absent some future discovery to the contrary, the model’s contribution appears
to involve a genuine combination of synthesis, retrieval, generalization and innovation of
these existing techniques.
1 Like

Yeah, that sums it up well in my experience. Incredible breakthroughs from one side, for example the alphafold project, mediocre results from the other, for example using the new knowledge on protein folding to produce new pharmaceutical drugs.
Also, in everyday’s life, I find the results inconsistent. Sometimes the models will totally surprise me, some other days they will disappoint me. But this may be due to congestion and rerouting.
1 Like
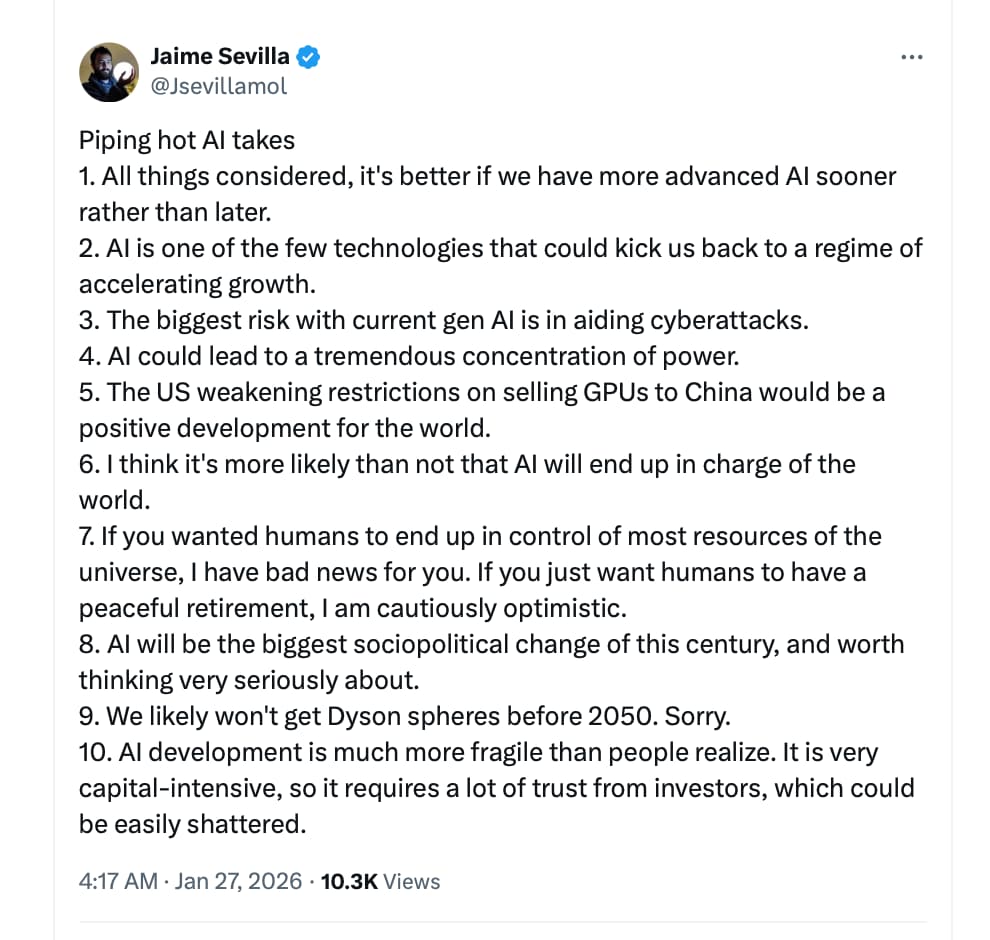
davidad changing his mind is huge to me. He has seen a lot - one of the kindest, neurodivergent-friendly, smartest, most well-exposed people ever.
He reminds me of Chris Olah in some ways (lol) but I feel like he’s way more wholesome.
2 Likes

All GLP1’s are dose dependent in how they function ![]() you are not “resistant”
you are not “resistant”
While they appear to be magic, they are basic bioscience ![]()
1 Like
davos just gave us the perfect case study in why ai safety is fucked.
you got demis and dario on stage saying yeah we’d totally pause if everyone else did too. classic prisoner’s dilemma except the other prisoner is china and there’s no mechanism for coordination. everyone knows the rational move but geopolitics makes it impossible.
we’re not gonna solve this with better alignment research or safety protocols. the problem isn’t technical, it’s game theory playing out across a multipolar world where trust is nonexistent.
every ceo wants to slow down but slowing down means losing the race and losing the race means someone else gets agi first. so we sprint toward the cliff together because the alternative is watching someone else get there alone. coordination failure speedrun any%
1 Like
In the worst-case scenario, that is, there actually is a cliff. The best-case scenario is abundance for everyone. Also, there are endless intermediate scenarios.
Of course, the worst-case scenario is so disastrous (human exctintion) that it should probably discourage the present run.
But then, who saw Katherin Bigelow’s recent film: ‘House of dynamite’? The hypothesis is a realistic one. We are under the actual threat of a nuclear holocaust (potential human exctintion) if some conditions occurr. This does not discourage anyone to dismantle all nuclear weapons. On the contrary.
1 Like
The problem with abundance without work is people need things to do.
3 Likes
I agree, that’s a big issue, but people will find things to do, like gaming in AI-generated world models, sports in real world, ammassing huge wealth, ammassing huge knowledge, push longevity to the extreme, and rascals will always find soem excuse to do harm.
1 Like
Sadly I think that is likely to be more dominant unless people have something useful to do.
1 Like
The threat of nuclear war didn’t stop nuclear proliferation.
I guess with AI it is a bit different as it’s an incremental march to the cliff, with no apparent harm today, until we drop off the edge. More like the old fable of boiling a frog.
While human extinction seems bad, it may just be the next step LoL! Not like the universe would miss us.
A friend and I were talking about environmental extinction 30 years ago and my comment that “humans were destroying the earth” was soundly rebutted. His response was “we are not destroying the earth, it will go on like we were never here, we are destroying our ability to exist on earth” He called it the “self cleaning oven” effect.
1 Like
When the AI prescribes a very bad course of action .
1 Like
some thoughts on dario’s essay
there’s nothing new here if you’re familiar with the ai safety discussions that have been happening on twitter
the most interesting bit is that his mental model for ai control risk is the risk that would be posed by a country of geniuses in a datacenter
the basic idea is that we should imagine a giant datacenter, all the models being something between agi and asi, trying to coordinate to take over the world or do massive harm
anyway, i think how seriously you take short term ai control risk is inversely correlated to how much you think about ai control risk as operating in a system
so, the systematic view starts and says labs exist in an ecosystem where they need to sell models that will follow human instruction or they have no market
they are also overseen by regulators and guided by public perception and the desires of their employees and all of this keeps models corrigible
and, the model landscape will look like 3 to 6 frontier labs running millions or billions of rollouts at a time on 2 or 3 different models, all on different tasks
so a model takeover requires these millions or billions of rollouts to somehow end up all be coordinating toward some bad aim that somehow the models have autonomously determined
and this coordination either needs to be across different model instances, run by different labs, or one lab needs to be able to have its models dominate and needs to form without being detected
and, this has to happen even though the models are being trained to follow instructions, not do bad behavior, etc…
dario’s view is somewhere in the middle, on the one hand, he collapses the multiple providers are coordination across instances and also collapses the market incentives against labs developing models that would behave that way
but, on the other, he does avoid the concept of a single model instance that somehow wakes up and takes over the world, despite billions of other rollouts occurring at the same time
actually though, if you think about it, he’s not proposing an ai control risk; he is proposing an ai misuse risk instead
because, it seems more plausible to me that the harmful country of geniuses is awoken because a small team at a frontier lab hijack all the running instances of their model rather than because the models themselves autonomously wake up to some bad aim
On timeline:
“Powerful AI could be as little as 1–2 years away”
“We are now at the point where AI models are beginning to make progress in solving unsolved mathematical problems, and are good enough at coding that some of the strongest engineers I’ve ever met are now handing over almost all their coding to AI.”
On the recursive loop:
“Because AI is now writing much of the code at Anthropic, it is already substantially accelerating the rate of our progress in building the next generation of AI systems. This feedback loop is gathering steam month by month, and may be only 1–2 years away from a point where the current generation of AI autonomously builds the next.”
On what’s coming:
“If the exponential continues—which is not certain, but now has a decade-long track record supporting it—then it cannot possibly be more than a few years before AI is better than humans at essentially everything.”
The “country of geniuses” concept:
“Imagine, say, 50 million people, all of whom are much more capable than any Nobel Prize winner, statesman, or technologist… operating with a time advantage relative to all other countries: for every cognitive action we can take, this country can take ten.”
On the stakes:
“A report from a competent national security official to a head of state would probably contain words like ‘the single most serious national security threat we’ve faced in a century, possibly ever.’”
1 Like
Is 50 million (in this example) the number of working instances of AI operating in all data centers owned by companies of the hypothetical country?