I have seen people raise some skeptical points about LLMs. I thought I would write some of my thoughts on this:
First, Transformers (the architecture that many LLMs use) are capable of much more than people think. They can execute algorithms where the memory is bounded by the context window length. This requires encoding the algorithms as a chain-of-thought (because the circuit depth for the computations is limited by the number of layers); and it requires using the context window to record an “execution trace” of the algorithm, along with any memory used.
People have furthermore proved that even just a linear autoregressive neural net with one non-linearly applied to choose the next token to output (a final softmax with temperature 0; i.e. argmax), can be trained to execute arbitrary algorithms. (To be a little more precise: given an algorithm to run, and given a sampling distribution of inputs, there exists an encoding of the algorithm by chains-of-thought, such that for every epsilon > 0 we can train that quasi-linear model for polynomial(1/epsilon, n) steps to where it correctly maps inputs to outputs running the algorithm for n steps, with probability > 1 - epsilon according to the sampling distribution). There are further theorems that show that you can specify the weights (up to some isomorphism class, and to within some specified error bound) of the model by choosing the training data distribution appropriately, and then the resulting output model should work for just about any data distribution.
The name of the game, then, is choosing the right training data. It appears we will soon run out of human-created data; however, synthetic data of various kinds will allow things to keep going further.
When synthetic data is mentioned people talk about the dangers of what happens when you feed a model’s output back into itself again and again, with noise amplifying at every stage (like the game of telephone or “Chinese whispers”). There are at least two objections to that. The first objection is that there are results showing that things don’t get so bad as long as you mix-in some fresh data at every step.
The second objection is that it depends on what kind of synthetic data we are talking about. e.g. systems that learn to get better and better at chess by playing against themselves don’t seem to suffer this problem. People like to then claim that it must be because you’re adding some “external grounding” in the form of a verifier that checks that the rules of chess are being adhered-to. However, there isn’t much information inherent in those rules. You can write them down on a napkin; and an LLM can even be trained to act as the verifier, and verify with nearly 100% accuracy.
This is where I make the distinction between two kinds of synthetic data: there is data that is predominantly declarative knowledge (like, what is the tallest mountain in the world?) that can’t just be deducted from other knowledge, and then there is procedural knowledge, or knowledge about how to do things (more efficiently).
If you keep feeding a model’s output back into itself as input its declarative knowledge might degrade; but you can produce an infinite supply of certain kinds of synthetic training data that should amplify its procedural knowledge.
How does this work? In a lot of cases it comes down to the fact that verifying a solution is easier than coming up with one to begin with. e.g. if you ask someone to sort a list of numbers, performing that sort is generally harder than just checking that the list is sorted. A model may have the skill of verifying that a list is sorted, but it may lack the skill of efficiently sorting a list. (It may be able to logically deduce what the sorted list has to be given enough time, and given its ability to verify that a list is sorted; but it may not be able to do this efficiently. Similarly, a chess program may be able to play a perfect game, given its ability to verify that the rules are being adhered to, but it may not be able to do this efficiently.)
Another set of methods that goes by the term “backtranslation” relies on the fact that in some cases it’s much easier to generate (input, output) training examples than to efficiently map an arbitrary input to an output. An example of this is generating anagram puzzle training examples: just pick a random word, like “tomato”. Then scramble the letters to maybe “atomot”. Now you have a training example (atomot, tomato). Here, you can be a good teacher, producing lots and lots of training examples, without being a very good student - just knowing how to generate examples doesn’t imply you can efficiently solve someone else’s example problems.
Generating example problems in a field like medicine or even creative writing is maybe harder, since there aren’t always easily-to-verify right answers. However, perhaps lots and lots of “unit tests” can serve as a “verifier” in this case. (Is this how that secret model that OpenAI built that is supposedly good at writing short stories works?)
Methods like the above, and then also the recent work on reasoning models, make me see there is still a lot of juice left in existing approaches – no breakthroughs required. When I reflect on all this, I come away thinking things will continue to improve at a breathtaking pace over the next several years.
“Onboarding” will be an important theme going forward. I think perhaps training models to do much better in-context learning over, say, 20,000 page “textbooks” will help with that. Making this all run efficiently might be the main challenge here. That might be where a breakthrough is required.
I don’t believe anyone whose probability has consistently been so high (or so low) for so long b/c it ignores the sheer complexity/uncertainty of the world (Elizer’s “object level” resolution isn’t as great as, say, Zvi). It’s extreme overconfidence which is an orange flag
They may be experts in their local area of computability theory/mathematics, but that doesn’t make them qualified to assess the massive amount of multimodal data+geopolitics+human psychology *outside their area of expertise that matters for outcomes.
Maybe Dan Hendrycks updating his p(doom) to 80% is indicative of smg, idk.
it’s also possible emergent properties will come out of AGI/ASI that somehow are able to align us to ourselves better (even some in Google think this), but recent geopolitical trends may make this way harder than before.

I’m reading “Empire of AI” right now…

I feel like we will have general purpose agents in 1 year, and 6 or 12 months after that agents that can help with research.
OpenAI and Google Deepmind produced LLM reasoning models that were able to achieve gold medal-level performance in the 2025 IMO [=International Math Olympiad]. Google Deepmind apparently had two systems that achieved this. One of the systems was implied to use a long prompt with lots of examples problems and instructions + in-context learning, similar to what I wrote above:
I think perhaps training models to do much better in-context learning over, say, 20,000 page “textbooks” will help with that.
Though, probably it wasn’t 20,000 pages of context (but it might have been!). The other Google solution didn’t use this. This is cleared-up in a Twitter / x thread by Deepmind’s Vinay Ramasesh:
https://x.com/vinayramasesh/status/1947391685245509890
It’s worth noting that a DeepThink system with no access to this corpus also got gold (again according to the official graders), with exactly the same score.
Also see Yi Tay’s (Google Deepmind) tweet:
https://x.com/YiTayML/status/1947392800884199761
Two points
- this is really just good old in context learning
- as already mentioned, another system without this also scored gold.
And the OpenAI solution appears to be a pure LLM without tools – no calculator, no access to Lean, no other kind of symbolic solver, no Python or programming interpreter, no internet, and possibly no separate tree-search module or anything like it (though that one I can’t confirm) – according to Sheryl Hsu (OpenAI):
https://x.com/SherylHsu02/status/1946478335212822839
The model solves these problems without tools like lean or coding, it just uses natural language, and also only has 4.5 hours. We see the model reason at a very high level - trying out different strategies, making observations from examples, and testing hypothesis.
Harmonic, another AI company, apparently also has a good showing in this competition:
https://x.com/HarmonicMath/status/1947023450578763991
So please join us live on @ x next Monday, July 28th at 3PM PT and hear from our CEO @ tachim and Executive Chairman @ vladtenev about the advent of mathematical superintelligence (and maybe a few surprises along the way).
Here’s a line‑by‑line unpacking of Holly Elmore’s thread and why AI‑safety folks keep repeating versions of this message.
1 “Nobody can know that ‘it’s over’ with AI risk”
- Epistemic humility is warranted. Even the best‑known quantitative risk assessments (e.g., Carlsmith’s 2022 report that put ≈10 % on an existential catastrophe by 2070) come with wide error bars and plenty of model uncertainty. (arXiv)
- Correlation ≠ destiny. We can see compute, data and algorithmic progress accelerating, but we still don’t know whether super‑human systems must be uncontrollable by default, or whether alignment techniques scale in tandem. Saying doom is “certain” claims far more knowledge than anyone actually possesses.
2 “I put ~15 % probability on us lucking out somehow”
Holly carves out a base‑rate for benign surprises:
Possible “luck” mechanisms Why some researchers assign non‑zero probability Unknown cognitive constraints – maybe super‑intelligence isn’t as power‑seeking by nature as we fear We don’t have empirical examples above human‑level generality; theoretical arguments rely on analogies and selection effects Economic brakes on scaling – power, H100 supply, or data scarcity might stall frontier model growth Studies suggest high‑quality data will run out and compute costs rise super‑linearly with capability (Epoch AI, arXiv) Strategic missteps by labs – bad research bets, failed fundraising, or regulation could slow things long enough for safety ideas to catch up The 2023 FLI “Pause” letter showed that even a six‑month hiatus was thinkable in public discourse (Future of Life Institute) Holly’s 15 % is deliberately lower than some AI‑optimist polls that imply a 40 – 50 % chance everything is fine, and higher than the most pessimistic voices who assign <1 % to luck. (Business Insider)
3 “We further might succeed at some combination of intentional efforts …”
This is the core AI‑safety program:
- Technical alignment research – interpretability, scalable oversight, constitutional training, etc.
- Governance & policy – compute licensing, red‑team requirements, model‑eval standards.
- Socio‑economic levers – liability law, insurance, antitrust pressure to reduce competitive races.
Holly’s claim that “it’s more likely than not we get some success” lines up with many safety practitioners who think partial wins (e.g., robust eval suites, capable early‑warning systems) substantially cut extinction odds even if perfect alignment remains unsolved.
4 “Luck and intentional interventions may work together …”
This is a complementarity argument:
- If scaling does stall for economic reasons (GPU shortages, energy limits, diminishing returns) (Reuters), that breather magnifies the value of policy or technical progress made during the lull.
- Conversely, if policymakers impose a frontier‑pause, it can give researchers time to bootstrap safety methods that themselves unlock further aligned capability—an iterative safety‑capability ladder.
5 “Don’t give in to fatalism … it’s not over ’til it’s over.”
Why AI‑safety advocates emphasize this:
- Psychological effect: fatalism erodes the political coalition required for regulations and the researcher morale needed for technical advances.
- Game‑theoretic effect: declaring doom inevitable can become a self‑fulfilling prophecy by disincentivizing investment in safeguards.
- Historical precedent: humanity has repeatedly mitigated existential‑scale risks (nuclear war, ozone depletion) through imperfect but real interventions; there is still running room for AI.
Big picture take‑aways
- 15 % luck is a floor, not a ceiling, for optimism.
- Governance and technical work plausibly add another ~20‑50 percentage‑points of survival probability, and these probabilities are controllable by human effort.
- Certainty of doom (or of safety) is over‑claiming. The rational stance is to treat AI safety as a high‑stakes, solvable problem whose outcome is still contingent on what labs, regulators, and researchers do in the next few years.
Holly’s thread is therefore a rallying cry: yes, advanced AI poses real existential risk, but believing “it’s already over” is neither accurate nor helpful.
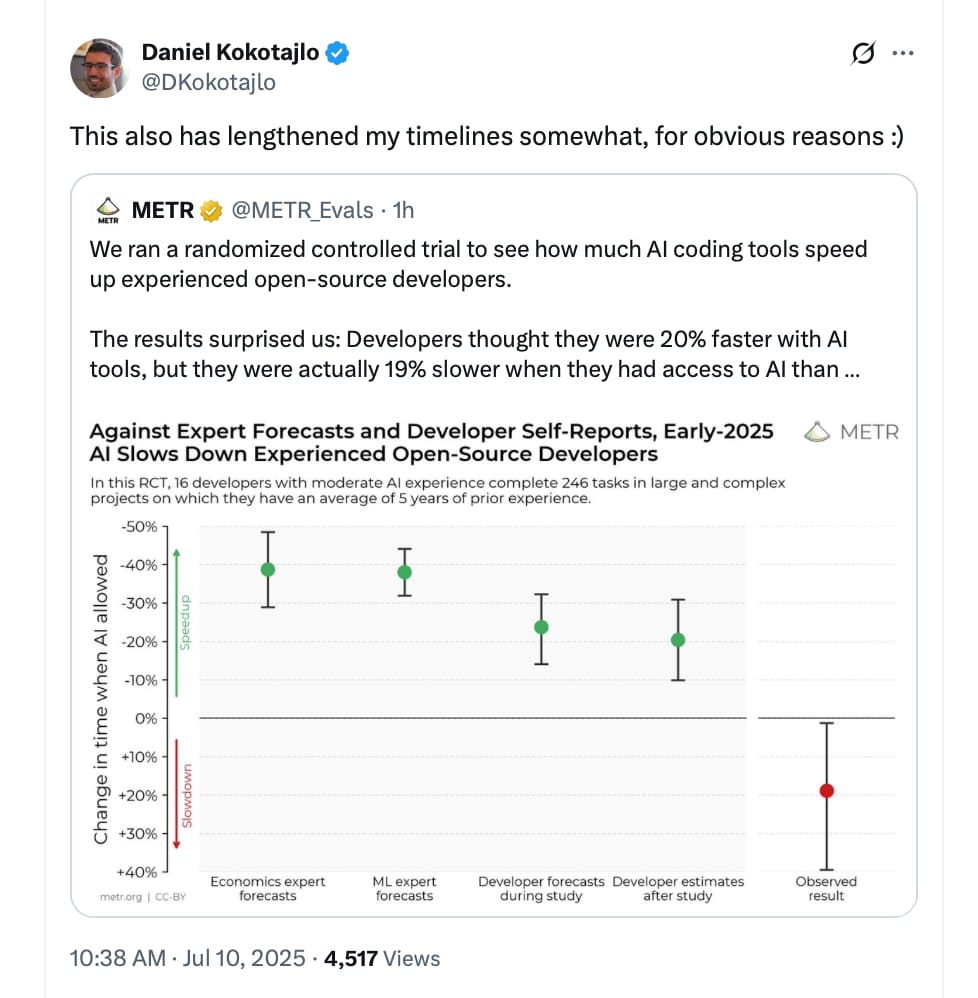
I wonder if superlongevity or disease curing drugs existed, we wouldn’t understand how and had to run human clinical trials anyway to know they’d work? Or maybe the solution can be grasped after it exists like how things are obvious in the rear view mirror? These two paragraphs also shows why mechanistic studies on complex diseases are subpar evidence in its current stage, and IMO interesting article about the Anthropic CEO Amodei (for those that didn’t know):
When Amodei left Princeton, the door to AI opened. He began postdoc work under researcher Parag Mallick at Stanford, studying proteins in and around tumors to detect metastatic cancer cells. The work was complex, showing Amodei the limits of what people could do alone, and he started looking for technological solutions. “The complexity of the underlying problems in biology felt like it was beyond human scale,” Amodei tells me. “In order to understand it all, you needed hundreds, thousands of human researchers.”
Amodei saw that potential in emerging AI technologies. At the time, an explosion of data and computing power was sparking breakthroughs in machine learning, a subset of AI that long held theoretical potential but had shown middling results until then. After Amodei began experimenting with the technology, he realized it might eventually stand in for those thousands of researchers. “AI, which I was just starting to see the discoveries in, felt to me like the only technology that could kind of bridge that gap,” he says, something that “could bring us beyond human scale.”
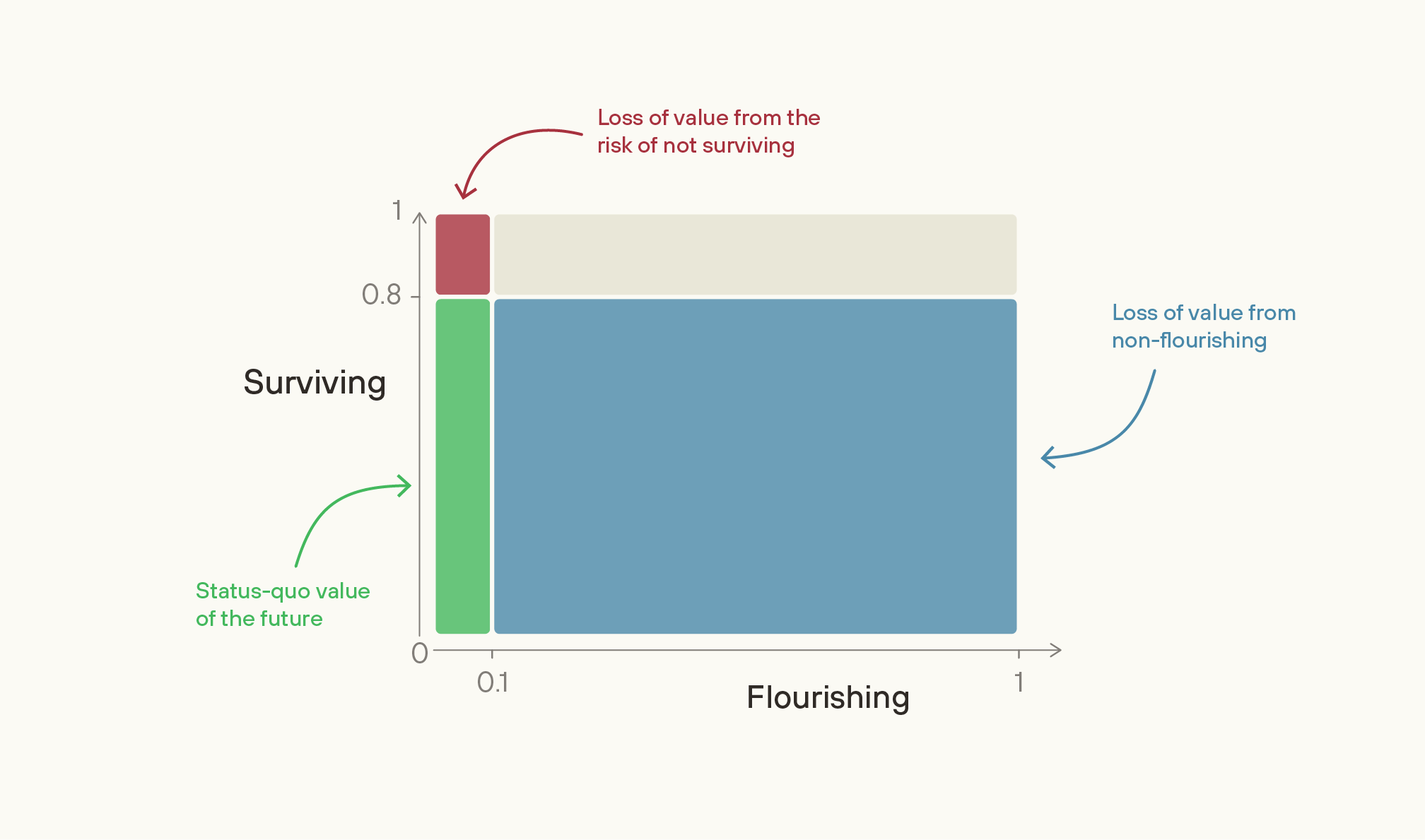
On these numbers, if we completely solved the problem of not-Surviving, we would be 20 percentage points more likely to get a future that’s 10% as good as it could be. Multiplying these together, the difference we’d make amounts to 2% of the value of the best feasible future.
In contrast, if we completely solved the problem of non-Flourishing, then we’d have an 80% chance of getting to a 100%-valuable future. The difference we’d make amounts to 72% of the value of the best feasible future — 36 times greater than if we’d solved the problem of not-Surviving. Indeed, increasing the value of the future given survival from 10% to just 12.5% would be as good as wholly eliminating the chance that we don’t survive.3
And the upside from work on Flourishing could plausibly be much greater still than these illustrative numbers suggest. If Surviving is as high as 99% and Flourishing as low as 1%, then the problem of non-Flourishing is almost 10,000 times as great in scale as the risk of not-Surviving. So, for priority-setting, the value of forming better estimates of these numbers is high.4
A central concept in my thinking about better futures is that of viatopia, which is a state of the world where society can guide itself towards near-best outcomes, whatever they may be.14 We can describe viatopia even if we have little conception of what the desired end state is. Plausibly, viatopia is a state of society where existential risk is very low, where many different moral points of view can flourish, where many possible futures are still open to us, and where major decisions are made via thoughtful, reflective processes. From my point of view, the key priority in the world today is to get us closer to viatopia, not to some particular narrow end-state.
That was a few minutes wasted.
This is an interesting video by AI Explained, a podcast on YouTube and Patreon that’s a few notches above what you’ll see in news media or most other podcasts, including ones run by experts. Listening to a few of this guy’s videos, he seems to have a lot more technical background that most other commentators, and he is just as often critical as he is upbeat about the state of AI. In this particular one he has an optimistic turn:
An ‘AI Bubble’? What Altman Actually said, the Facts and Nano Banana

One of the takeaways from this video is that CEOs don’t really have the best insight about what their models can do and will do even just a few months later. For example, he mentions:
you’ve got Sundar Pachai the CEO of Google who I remember distinctly saying that progress would be slower in 2025 than it was in 2024. But then Google DeepMind went beast mode after that and started releasing eye-opening models almost weekly from around I’d say mid-June. He clearly didn’t know what was coming.
…
Regarding skeptics, here’s a line from a recent Ezra Klein opinion piece for the New York Times, titled “How ChatGPT Surprised Me” that I thought was funny:
In some corners of the internet — I’m looking at you, Bluesky — it’s become gauche to react to A.I. with anything save dismissiveness or anger.
Here’s a video from about a month ago that interviews Chris Szegedy, an AI researcher (and mathematician) who was a leading researcher at Google a few years back, then left and has done other things (I think including helping to co-found x.ai, though he doesn’t work there anymore):

He’s been pretty bullish about highly intelligent AI that can solve scientific problems for a while now, and even has money bets with Gary Marcus (Marcus is skeptical at the rate of progress, Szegedy is insistent that it’s going a lot faster than people think).
Recently, a company he co-founded cleaned-up the autoformalization of a strong form of the Prime Number Theorem (I.e. mapping a natural language proof into a version in Lean that can be verified by computer). Terry Tao and others were involved in autoformalizing a weaker version of the theorem, and left it as a challenge to complete the project, perhaps expecting it would take 2 years or more. Szegedy and his team used AI to complete it in a matter of weeks.
He seems to think we will have “superintelligent” systems in different domains, including math, before the end of 2026.
…
Separately, some leading researchers in CS theory are pretty bullish about cracking the hallucination problem, at least for most of the important types. They seem to think it’s now a downhill battle, and it’ll go pretty quick.
This is an interesting interview with Microsoft’s Mustafa Suleyman (who was also a co-founder of Deepmind) on Alex Kantrowitz’s podcast / YouTube channel, titled " Could LLMs Be The Route To Superintelligence?". In this interview Suleyman sounds more grounded and focused on technical predictions than I recall hearing from him in the past:

He mentions how Microsoft has all of OpenAI’s IP, and then when pressed about whether Microsoft can overcome data and energy barriers, he says (8 minutes, 53 seconds in):
We are not data-constrained right now. We are generating vast amounts of high-quality synthetic data, which is proving to be useful. Obviously, again, the same is also true… like, more high-quality data would be great; but I don’t see a slowing down of progress because of either of those two things.
When pressed about Microsoft’s plans to speed ahead towards “super-intelligence” while labs haven’t even yet nailed-down “AGI”, it seems his conception of super-intelligence is about systems endowed with some general reasoning capability and knowledge, that are super-human in a small number of areas; but that lack some of the planning and agentic capabilities that would make them potentially a threat. He says (starting 4 minutes, 44 seconds):
We’re starting off saying, what specific tasks are we trying to optimize? And, you know, the project of humanist super-intelligence is, first, trying to say what good will this technology do and how will it be safe and controllable and aligned to human interests. And one of those dimensions of safety is verticalization. If a model has been designed explicitly to achieve medical super intelligence, then by definition it isn’t going to be the best software engineer in the world, it isn’t going to be the best mathematician or physicist. And so narrowing the domain, not too much, not entirely because you can’t collapse it, but narrowing it and reducing the generality is one of the ways that I think um is likely to help create more control.
When asked whether he thinks you need some breakthrough new architecture and fancy “world models”, he says, no, LLMs and Transformers (where he includes multi-modal training) are good enough, and seem to be the direction Microsoft is heading in; though, he suggests that tweaks and reshapings of those core models will take place. Around 12 minutes, 28 seconds in Kantrowitz asks him:
So your perspective basically is that LLMs are the path, that we don’t need another breakthrough that’s a different model format to get to super-intelligence.
Suleyman responds:
Well, I mean so far… no, I don’t think so…
This is another video by “AI Explained” about Google’s new image synthesis model:

It looks really impressive! The images are good enough now to be used in professional applications, seemingly requiring complicated reasoning to achieve.
He got early access, and at the end of that video he says:
Imagine an image generated by Nano Banana Pro and animated by Veo 4 potentially coming out by the end of this year.
Did he also get early access to Veo 4? He shows what Veo 3.1 can do, but Veo 4 might be another leap beyond that, approaching Hollywood-grade video synthesis.
How long will it be until whole movies are synthesized that are Hollywood-grade? What about doing it in 3D so that people can explore it in VR? What about Matrix-like scenes one can interact with in VR?
At the rate things are developing, I wouldn’t be surprised if some of these are achieved in the next few years.
Looks like the co-founder of the Stop AI group has left it:
https://xcancel.com/StopAI_Info/status/1992286218802073981#m
Stop AI is deeply committed to nonviolence and protecting human life by achieving a permanent global ban on artificial superintelligence.
Earlier this week, one of our members, Sam Kirchner, betrayed our core values by assaulting another member who refused to give him access to funds. His volatile, erratic behavior and statements he made renouncing nonviolence caused the victim of his assault to fear that he might procure a weapon that he could use against employees of companies pursuing artificial superintelligence.
We prevented him from accessing the funds, informed the police about our concerns regarding the potential danger to AI developers, and expelled him from Stop AI. We disavow his actions in the strongest possible terms. We are an organization committed to the principles and the practice of nonviolence. We wish no harm on anyone, including the people developing artificial superintelligence.
Later in the day of the assault, we met with Sam; he accepted responsibility and agreed to publicly acknowledge his actions. We were in contact with him as recently as the evening of Thursday Nov 20th. We did not believe he posed an immediate threat, or that he possessed a weapon or the means to acquire one. However, on the morning of Friday Nov 21st, we found his residence in West Oakland unlocked and no sign of him. His current whereabouts and intentions are unknown to us; however, we are concerned Sam Kirchner may be a danger to himself or others. We are unaware of any specific threat that has been issued.
We have taken steps to notify security at the major US corporations developing artificial superintelligence.
We are issuing this public statement to inform any other potentially affected parties.
What was he going to use the funds to do? Buy weapons?
Anyways, we’ll probably see more of that the more advanced AI gets.
(Chatgpt is also bad at China forecasts)
Gemini 3 pro is much more bullish on LEV by 2055…
[there’s some underestimation of pandemic risk, which might wipe out a substantial fraction of the human population but not all]